
David Konatschnig
Principal Architect
Apache Kafka ist in aller Munde, zunehmend auch in Schweizer Firmen aus allen Sektoren. Das Interesse kommt sowohl aus den IT-Abteilungen als auch vom Management. Mit Schlagwörtern wie Hochverfügbarkeit, Skalierbarkeit, Fehlertoleranz und High Performance wird die ursprünglich von LinkedIn entwickelte Message-Streaming-Plattform angepriesen. Doch was steckt dahinter? Ist das Interesse gerechtfertigt? Gibt es tatsächlich einen geschäftlichen Nutzen? Dieser Blogpost soll Licht ins Dunkel bringen, aufzeigen wie Kafka funktioniert, wie es sich von anderen Messaging-Systemen differenziert und wo sich Use Cases finden.
Autor: David Konatschnig
Apache Kafka ist eine verteilte Stream Processing und Messaging Plattform, die sich für die Verarbeitung von Echtzeit Datenströmen (sog. Stream Processing) eignet. Entwickelt wurde die Plattform bei LinkedIn. Dies, weil die klassischen Messaging-Systeme zu der Zeit den eigenen hohen Anforderungen (in erster Linie bzgl. Fehlertoleranz und Skalierbarkeit) nicht gerecht wurden. Mit der Eigenentwicklung wurde wichtige Pionierarbeit geleistet. Später wurde Kafka durch die Apache Foundation als Open-Source-Projekt weiterverfolgt. Kafka ist ein Publish-Subscribe-System, das auf hohe Performanz bezüglich Nachrichtendurchsatz und -latenz ausgelegt ist. Es bietet unter anderem folgende Funktionalitäten:
Der Ausdruck «verteilte Streaming Plattform» beschreibt, dass Kafka in einem Cluster, bestehend aus mehreren Servern (sog. Broker), betrieben werden kann. Ein grosser Vorteil von Kafka ist, dass es sehr flexibel auf günstiger Hardware (sog. Commodity-Hardware) oder auch in Containern betrieben werden kann und kein teures, dediziertes Setup voraussetzt.
Daten, die mittels Apache Kafka transportiert werden, werden in sogenannten «Topics» gespeichert. Das kommt eigentlich aus der Welt der relationalen Datenbanken. Man kann sich ein Topic wie eine Tabelle vorstellen. Diese werden von sogenannten Producern beschrieben und von den sogenannten Consumern bzw. Konsumenten gelesen. Topics sind in Partitionen unterteilt, wobei diese auf mehrere Broker verteilt sind. Das erlaubt ein Auslesen der Daten parallel von einem Topic.
Hier kommt auch gleich ein wichtiger Unterschied zu klassischen Messaging-Systemen ins Spiel: Bei ihnen werden typischerweise Nachrichten, sobald sie von allen Konsumenten gelesen wurden, aus der Queue gelöscht. Bei Kafka hingegen, hat ein Topic, eine nach Dauer konfigurierbare Lebenszeit der Speicherung (Retention Time). Wird diese erreicht, werden Nachrichten, die älter sind, von der Festplatte gelöscht. Solange die Nachricht aber im Topic ist, kann sie beliebig oft und von beliebig vielen Konsumenten gelesen werden. Dabei kann das ganze Topic oder ein Teil davon ab einem bestimmten Offset gelesen werden. Kafka übergibt somit die Verantwortung darüber, welche Daten bereits konsumiert wurden, komplett an den Konsumenten. Konkret heisst das, dass ein Topic gleichzeitig von einer Echtzeit Applikation, einem Batch-Prozess und einem Machine-Learning-Algorithmus gelesen werden kann.
Apache Kafka hat den Anspruch, das zentrale Nervensystem innerhalb einer Unternehmung zu werden, welches alle Daten und Systeme miteinander verknüpft. Dabei sollen die Daten in den Mittelpunkt gerückt werden, hin zu einer ereignisgesteuerten Architektur. Dies soll sowohl für Start-ups wie auch für Grosskonzerne funktionieren.
Mit Apache Kafka kann zweierlei erreicht werden: Einerseits kann man Silos aufbrechen, indem man alte, schwerfällige Backend-Applikationen anzapft und Datenänderungen in Sekundenschnelle in der Unternehmung publizieren kann. Andererseits kann man auch ganz neue Use Cases umsetzen, die bis anhin aus technischen Gründen nicht oder nur mit Einschränkungen möglich waren. Zum Beispiel die Echtzeitanalyse von Clickstream oder Transaktions-Daten.
In der heutigen, schnelllebigen Zeit will man umgehend auf ein Ereignis reagieren können. Bedenkt man die vielen Einflüsse, beispielsweise durch Klicks und Likes von Social Media, oder Messdaten von IoT Geräten, dann ist man mit einem klassischen ETL-Prozess, der die Daten nur alle 24 Stunden aufbereitet, der Konkurrenz immer einen Schritt hinterher. Mit Kafka als zentrales Nervensystem kann auf sämtliche Ereignisse, wie beispielsweise API Requests oder Datenbank Updates, zeitnah reagiert sowie ein Prozess ausgelöst oder ein Microservice angesteuert werden.
Schaut man sich beispielsweise den Finanzsektor an, so gibt es unzählige Use Cases, die einen echten Mehrwert für den Kunden bieten können, wie beispielsweise Fraud-Detection anhand von Echtzeit-Auswertung von Transaktionen oder Echtzeit-Währungsumrechnungen für getätigte Einkäufe. In der Automobilindustrie kann anhand von Sensordaten im Fahrzeug alarmiert werden, sobald eine Komponente ausgewechselt werden sollte und wo sich der nächste Serviceanbieter befindet.
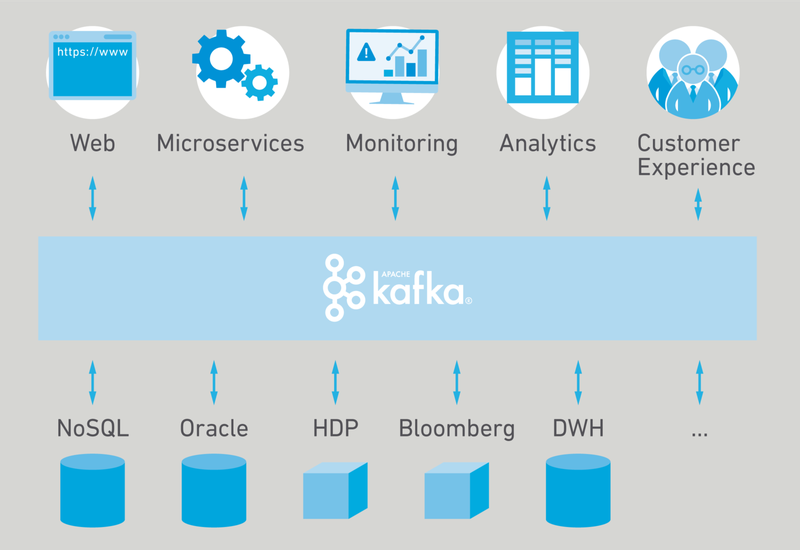
Kafka ist nicht einfach ein weiteres Messaging-System, das mit der Konkurrenz im Markt mitmischt. Es bietet einige wesentliche Unterschiede, die einen immensen Einfluss auf die Infrastruktur-Betriebskosten sowie die User Experience haben – so hebt sich Apache Kafka auf eine eigene Stufe hoch. Folgend ein Überblick über die wichtigsten Alleinstellungsmerkmale:
Apache Kafka ist definitiv mehr als nur ein Hype. Wie bei jeder neuen Technologie muss man natürlich hin und wieder Erwartungsmanagement betreiben. Doch immer mehr Unternehmen realisieren, dass sie digitale Services anbieten können, die innovativ und disruptiv sind, wenn die richtigen Daten bereitgestellt und integriert werden. Hier kann sich Apache Kafka von gängigen Messaging-Systemen abheben, da es einen höheren Datendurchsatz, höhere Verfügbarkeit und bessere Skalierbarkeit bietet. Dies schlägt sich beispielsweise direkt bei der User Experience nieder, indem neue Services, die Echtzeitdaten verwenden, angeboten werden können.