Simon Flühmann
Principal Consultant
Ich behandle in diesem Beitrag vier verschiedene Ansätze zur Datenhaltung bei Microservices.
Autor: Simon Flühmann
Die Verwendung einer gemeinsamen Datenbank für alle Microservices einer Applikation würde sich traditionellerweise anbieten. Die Vorteile einer zentralisierten Datenbank haben sich im Software Design bewährt und sind offensichtlich: Daten eines Systems stehen allen Modulen jederzeit und auf dem aktuellsten Stand zur Verfügung. Konsistent ist hier kein Problem. Hinzu kommt ein einheitliches Datenformat: Eine Einigung auf ein gemeinsames Schema ist zwar ein Kompromiss, vereinfacht jedoch die Entwicklung und die Wartung enorm.
Trotzdem sollte bei der Umsetzung einer Microservice-Architektur aus den folgenden Gründen vor dem Einsatz eines zentralisierten Speichersystems abgesehen werden:
Microservices sollten also in Bezug auf Daten entkoppelt sein. Dies konsequent umzusetzen ist aber schwer – gerade im klassischen Betrieb ist das Pflegen einer Applikation mit polyglotter Persistenz sehr aufwändig, da für jede Technologie die gesamte Betriebs-Organisation aufgebaut und in Gang gehalten werden muss (SLAs, Backup, Recovery, Wissensaufbau, 2nd Level Support). DevOps bringt hier natürlich etwas Entlastung.
Falls auf die Vorteile einer zentralen Datenbank nicht verzichtet werden kann, bietet der Einsatz von vollständig getrennten Schemata pro Microservice innerhalb einer Datenbank einen Mittelweg. So sind die Anforderungen punkto getrenntes Datenmodell und Entkopplung architektonisch erfüllt und die genannten Nachteile fallen weg.
Doch damit treten neue Schwierigkeiten auf. Um die Anforderung an Konsistenz unter den Microservices zu erfüllen, müssen die Daten aufwändig repliziert und die Datensätze in andere Schemata konvertiert werden, um sie in einer Integration-DB zu speichern. Das möchte man eigentlich vermeiden, denn die Schema-Transformationen sind teuer und auch der Netzwerkverkehr hemmt die Performanz zusätzlich. Weiter wird mit diesem Ansatz auch die Widerstandsfähigkeit beeinträchtigt. Die gemeinsame Datenbank wird zum Single-Point-of-Failure und ein Ausfall resultiert aufgrund der hohen Kopplung in einem Service-Unterbruch der ganzen Applikation.
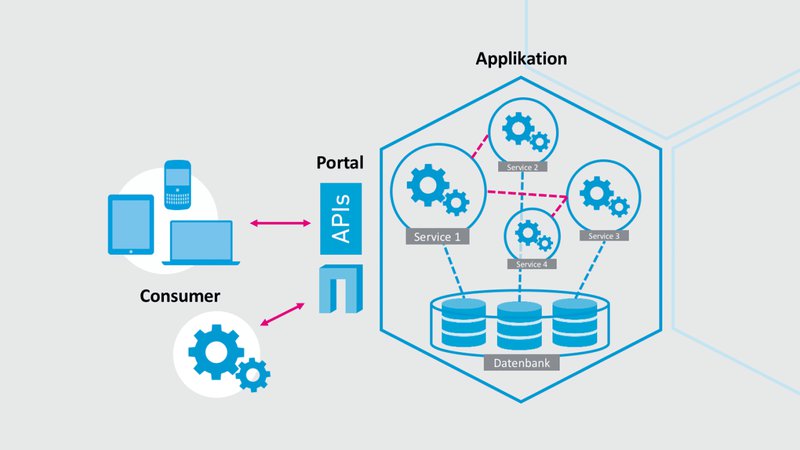
Zusammenfassend ist Festzuhalten, dass das Führen einer zentralen Datenbank konträr zum Leitgedanken der Entkopplung von Microservices ist und diverse Stolpersteine mit sich bringt. Der Einsatz getrennter Schemata einer zentralen Datenbank kann zwar in gewissen Anwendungsfällen die richtige Wahl sein. Grundsätzlich ist jedoch davon abzuraten ein Microservice-Systems zu betreiben, ohne dedizierten Data-Store pro Service. Eine zentrale Datenbank macht die gewichtigsten Vorteile eines modularen Designs zunichte.
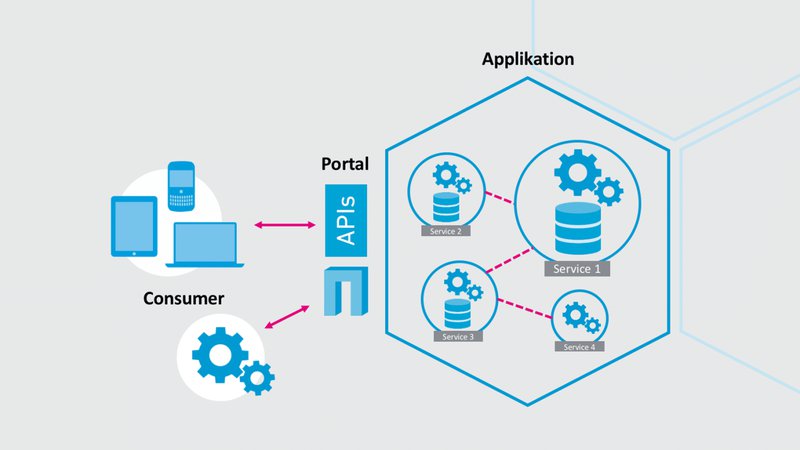
Vollständige Entkopplung und daraus folgende Autonomie sind die wichtigsten Eigenschaften von Microservice-Architekturen. Im besten Fall implementiert also jeder Microservice eine eigene Lösung zum Persistieren seiner Daten. Damit ist das Paradigma der Datenhoheit eines jeden Microservices erfüllt. Weiter kann eine zur Business-Logik perfekt passende Persistenz-Technologie gewählt werden. Dieser Ansatz verspricht hochverfügbare Daten und starke Ausfallsicherheit. Die Skalierung der Datenspeicher ist sehr komfortabel – unterstützt durch automatisiertes, autonomes Deployment aller Module. Die Kommunikation zwischen den Microservices geschieht über APIs. Wählt man diesen Ansatz, geniesst man alle Vorteile einer Microservice-Architektur.
Typisch für hochverteilte Systeme besteht hier jedoch das Risiko von inkonsistenten Daten – man spricht von «eventual consistency». Es können nicht alle Datenspeicher über ganzen Software-Kontext laufend ihre Zustände synchronisieren. Die Konsequenz kann sein, dass ein Microservice nicht mit aktuellen Daten arbeitet. Auch können häufige Berechnungen und Datenabfragen über APIs unter Umständen zu verminderter Leistungsfähigkeit des Systems führen. Ein weiterer Nachteil dieses Ansatzes ist, wie bereits erwähnt, der erhöhte Aufwand für den Betrieb.
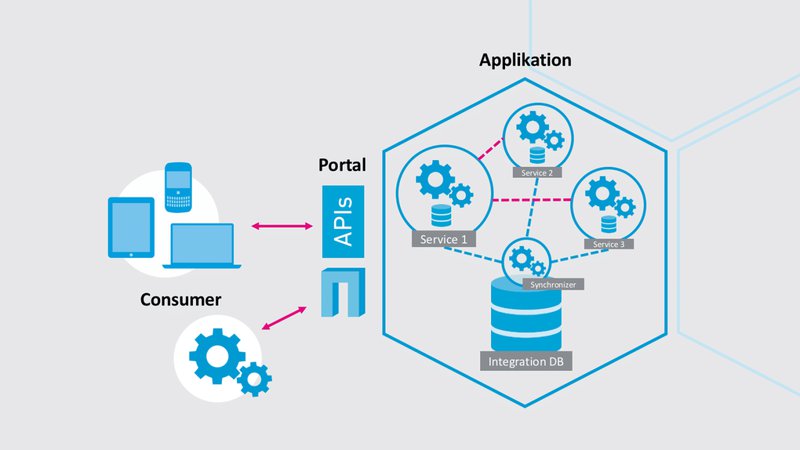
Die Konsistenz von Daten unter den Microservices kann mit Replication erreicht werden. Dazu wird der Ansatz autonomer Datenbanken «per Service» mit einem Replication-Job ergänzt. Dieser repliziert periodisch die Zustände der Microservices, transportiert diese in ein einheitliches Datenmodell und sorgt für einen synchronisierten Datenbestand in einer Integration-Datenbank, von welcher aus die Zustände im System wieder aktualisiert werden.
Diese Herangehensweise löst das Problem der inkonsistenten Daten teilweise. Konsistenz bleibt aber auch hier eine Utopie. Bis die Daten im gesamten System repliziert sind, kann es einige Zeit dauern. Die Charakteristik der «eventual consistency» ist in jedem Fall zu berücksichtigen.
Die besprochenen Ansätze sind punkto Performanz und Konsistenz nur teilweise zufriedenstellend. Ein neuer Ansatz ist Event Sourcing. Traditionellerweise werden in Datenbanksystemen die aktuellen Zustände von Datensätzen mittels CRUD-Operationen verwaltet. Lediglich der letzte Zustand eines Datensatzes wird gespeichert, indem der vorhergehende Zustand überschrieben wird. Im Gegensatz dazu speichert man mit Event Sourcing keine Zustände (stateless), sondern eine Abfolge von Ereignissen, die zum aktuellen Zustand des Objekts geführt haben.
Jeder beliebige Zustand in der Historie des Microservice kann durch eine erneute Ausführung der Events wiederhergestellt oder beispielsweise auf einer anderen Plattform repliziert werden.
Event-driven Data Management bringt in Zusammenhang mit Microservices entscheidende Vorteile:
..aber auch Challenges:
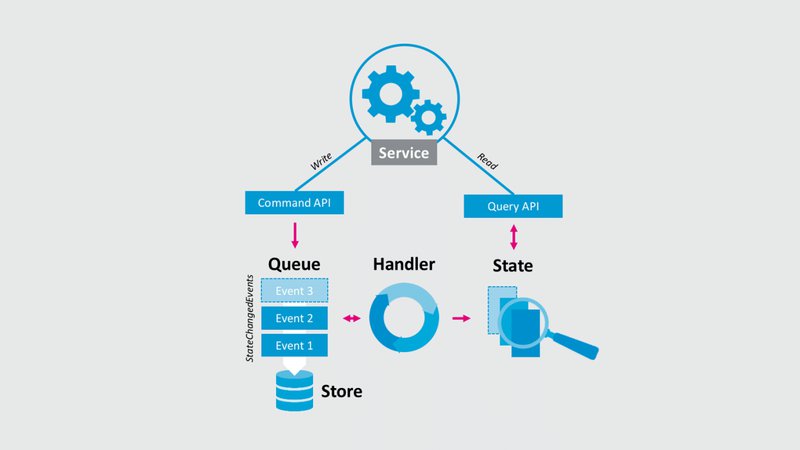
Im Zusammenhang mit Event Sourcing muss ein weiteres Pattern genannt werden: Command Query Responsibility Segregation (CQRS). Es handelt sich hierbei um ein Architekturmuster, das eine Anwendung intern in zwei Zuständigkeitsfelder aufteilt: in den Command-Teil und in den Query-Teil. Im Command-Teil werden Zustandsänderungen verarbeitet, während der Query-Teil nur dafür verantwortlich ist, viele Lese-Abfragen schnell und effizient durchzuführen. Durch die erneute, interne «Separation of Concerns» von Lesen und Schreiben wird neben Verminderung von Komplexität im Gesamtkontext ein zusätzlicher Performance Gewinn erzielt.
Falls weitere Microservices Zugriff auf die Daten eines Moduls benötigen, können Events abonniert werden, um auf einen «StateChangedEvent» zu reagieren oder die Daten werden über die Query-API des Microservice abgefragt. Gegebenenfalls ist in der Applikation auch ein gemeinsamer Message-Broker vorhanden, in dem die Daten zentral abgeholt werden können.