Kann eine Data- und Analytics-Plattform Cloud-native gebaut werden?
Eine Data- & Analytics-Plattform ist ein komplexes Gebilde und wird von Experten bedient. Ob diese Cloud-native gebaut werden kann, erfahren Sie in diesem Blog.
Autor: Adam Szendrei
Was braucht es für eine Data- und Analytics-Plattform in der Cloud?
Um es gleich vorweg zu nehmen: Ja, auch eine komplexe Werkzeug-Landschaft, wie es eine Data- und Analytics-Plattform ist, lässt sich Cloud-native aufsetzen. Die beiden grossen Vorteile eines solchen Ansatzes sind:
- Die vielen verschiedenen Werkzeuge werden vom Cloud-Anbieter gemanaged. Der Aufwand für das Aufsetzen und den Betrieb der Plattform ist so viel geringer.
- Die Entwicklung ist durch standardisierte Prozesse und Schnittstellen viel besser zugänglich für unterschiedliche Nutzergruppen.
Im Detail ist das Thema sehr komplex:
-
Wie wird die Plattform skaliert?
-
Sind die Daten stets aktuell?
- Wie behält man den Überblick bei den Daten und hat die Kosten im Griff?
- Ist die Plattform sicher genug?
- Wie werden die Anwendungen deployed?
- Wie wird auf der Cloud ein sauberes Staging der Daten abgebildet?
Solche Fragen müssen beantwortet werden, wenn eine Data- und Analytics-Plattform aufgebaut werden will, on premises wie auch in der Cloud.
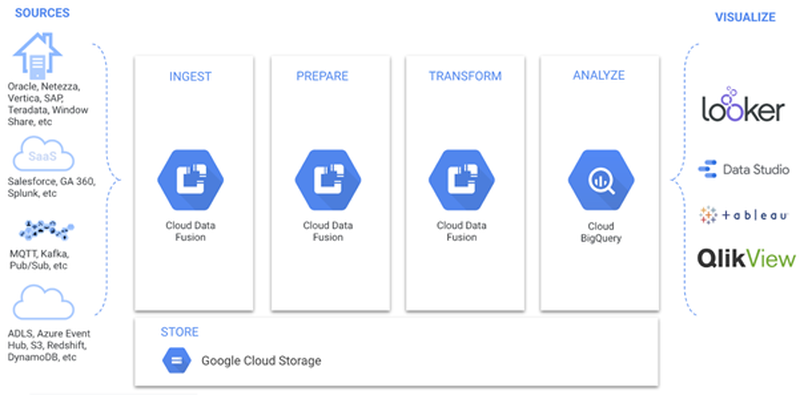
Abbildung 1 zeigt die typischen Verarbeitungsstufen eines Analytics-Projektes:
- Ingest: Integrieren verschiedener Datenquellen und -typen
- Prepare: Vorbereiten der Daten für die weiteren Prozesse (z.B. cleansing, filtering, etc.)
- Transform: Aggregieren und Kombinieren der Daten und damit neue Daten erschaffen
- Analyze: Analysieren der Daten und Erkenntnisse gewinnen
- Visualize: Visualisieren der Daten und Erkenntnisse mit einem Business-Analyse- Werkzeug
Wie erwähnt, sollte jede Data- und Analytics-Plattform diese Themen und Bereiche abdecken und die oben formulierten Fragen zufriedenstellend beantworten können. Im nächsten Abschnitt stellen wir vor, wie Google diese Herausforderung angeht.
Warum sollte der ETL-Prozess (Extract, Transform, Load) in der Cloud durchgeführt werden?
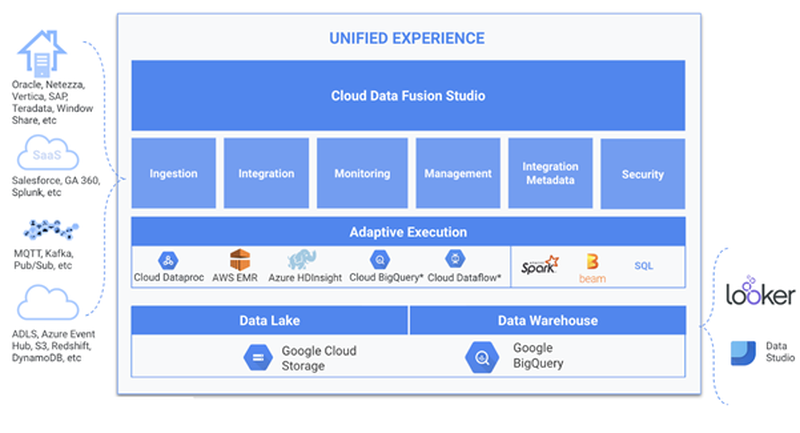
Die Antwort von Google auf die Data- und Analytics-Plattform ist Cloud Data Fusion. Es handelt sich hierbei um eine Sammlung von Werkzeugen, mit welcher einerseits traditionelle Datenverarbeitung (z.B. ETL mit Spark) gemacht werden kann. Andererseits können jedoch auch grosse Datenmengen mit einer kurzen Latenzzeit verarbeitet werden. Google Cloud Data Fusion ist eine Google Cloud Plattform, auf welcher Code Free ETL Pipelines via eines Drag and Drop Interface entwickelt werden können. Cloud Data Fusion übersetzt die visuell erstellte Pipeline in einem Apache Spark- oder MapReduce-Programm, welches Transformationen parallel in einem kurzlebigen Dataproc-Cluster ausführt. Auf diese Weise können auf einfache Weise komplexe Transformationen über grosse Datenmengen skalierbar und zuverlässig realisiert werden, ohne die Infrastruktur verwalten zu müssen. Cloud Data Fusion ist vergleichbar mit Google Dataflow. Dataflow ist auch ein Dienst für die parallele Datenverarbeitung, sowohl für Batch- als auch für Stream-Verarbeitung. Es verwendet jedoch Apache Beam an Stelle von CDAP und kann mit wenigen Code-Modifikationen von einem Batch zu einer Stream Pipeline wechseln. Abbildung 2 zeigt den Aufbau der Cloud Data Fusion-Plattform.
Was sind die Vorteile, eine solche Plattform as-a-Service zu beziehen?
Datenanalysten, Data Scientisten oder Business Analysten, die sich gewohnt sind, auf der althergebrachten DWH-Infrastruktur des Unternehmens direkt in Datenbanken zu arbeiten, werden sagen: “Wir haben doch viel mehr Flexibilität und auch Agilität, wenn wir das selbst aufsetzen und betreiben.” Ist da was dran? Wir sagen jein. Auf jeden Fall sprechen folgende Gründe sehr stark für einsatzfertige Plattformen:
- Cloud Data Fusion ermöglicht ein einheitliches Bild über die Daten-Pipelines und Datenprojekte in der Google Cloud. Egal ob Entwickler, Data Engineer oder Business Analyst, jeder kann sich auf seine Inhalte konzentrieren. Dafür stehen unterschiedliche Interfaces von Code bis zu Drag-and-Drop-GUI-basierten Design-Werkzeugen zur Verfügung.
- Die Plattform ist offen. Open-Source wird grossgeschrieben. Die Technologie CDAP ermöglicht die Übertragbarkeit in eine Hybrid- und Multi-Cloud-Umgebung. Dafür werden im Hintergrund Dataproc Cluster zur Ausführung von Code beigezogen.
- Die Google Infrastruktur bietet mit seinem Petabyte Network und seiner Storage Kapazität fast endlose Skalierbarkeit. Cloud Data Fusion erfindet die Welt nicht neu, sondern integriert viele bekannte Technologien wie z.B. Google Kubernetes Engine (GKE), Cloud SQL, Cloud Storage, Persistent Disk oder Cloud Key Management Service.
- Mit BigQuery und TensorFlows stehen performante Analysewerkzeuge zur Verfügung.
- Die Zukunft ist Serverless. Warum sollte für ein Service bezahlt werden, welcher nicht genutzt wird? Beispielsweise steht hinter BigQuery ein einfaches und transparentes Pricing-Modell, bei welchem die Kosten der Abfragen und der dazugehörige Speicherplatz von Beginn an abgeschätzt werden können.
- Das Thema Realtime wird immer wichtiger. Mit Cloud Data Fusion können Batch und Realtime ETL/ELT Pipeline transparent gemischt werden. Im Hintergrund laufen MapReduce, Spark oder Spark Streaming Pipelines ab.
- Cloud Data Fusion bietet durchgehendes Handling von Metadaten. Data Lineage kann über die integrierte Plattform nahtlos aufgebaut werden und einzelne Attribute können bis zur Quelle zurückverfolgt werden
Fazit
Zusammenfassend kann gesagt werden, dass der Einsatz von ETL-Technologien in Cloud-nativen Umgebungen viele Vorteile gegenüber einer selbst unterhaltenen on premises Variante bringt. Ein kleines Defizit bezüglich Flexibilität wird dabei bei weitem aufgeholt. Das Mass an Portabilität ist bei Google Data Fusion genügend hoch, so dass man auch nicht einem starken Lock-In zum Opfer fällt.
Ihr ipt-Experte
Ich freue mich auf Ihre Kontaktaufnahme