
Mario Maric
Lead Consultant
In diesem Blog erläutere ich die wichtigsten Architekturmuster und Anwendungsfälle, in denen Kafka zum Einsatz kommt.
Autor: Mario Maric
Bezeichnend für diese Technologie ist deren Vielseitigkeit. Nebst der Realisierung von ereignisgetriebenen Architekturen (EDA), gibt es verschiedene Ausprägungen von Integrationsmustern, die mit Kafka umgesetzt werden können. Event Sourcing, Event Distribution und Event Processing sind typische Ausprägungen einer EDA. In vorliegendem Beitrag gehe ich aber auf die weniger bekannten Anwendungsgebiete Stammdaten Integration, Mainframe Offloading und Audit Trail ein.
Die Stammdaten-Integration ist ein altbekanntes Problem der Enterprise Integration. In modernen Applikationslandschaften, gewinnt dieses Thema immer mehr an Bedeutung. Es gilt, weniger agile Backend Applikationen mit schnelllebigen Frontend Applikationen zu verbinden. Mittels der zentralen Bereitstellung der Daten über Event Streaming kann dies bewerkstelligt werden. Replikation von Daten ist kein Unding mehr. Die Technologie und Tragfähigkeit von Kafka ist heute so weit fortgeschritten, dass man Daten fast beliebig schnell und oft replizieren kann.
Die grösste Herausforderung bei dieser Art der Integration ist die geeignete Transformationslogik, die auf der einen Seite eine einfach wartbare Integrationsschnittstelle darstellt, auf der anderen Seite dem Frontend aber möglichst viel Flexibilität ermöglicht. Vereinfacht gesagt, will man den standardisierten Backend Prozess im Frontend möglichst flexibel ausgestalten und mit Intelligenz anreichern. Dafür eignet sich die kontextbezogene Integration mit Event Streaming.
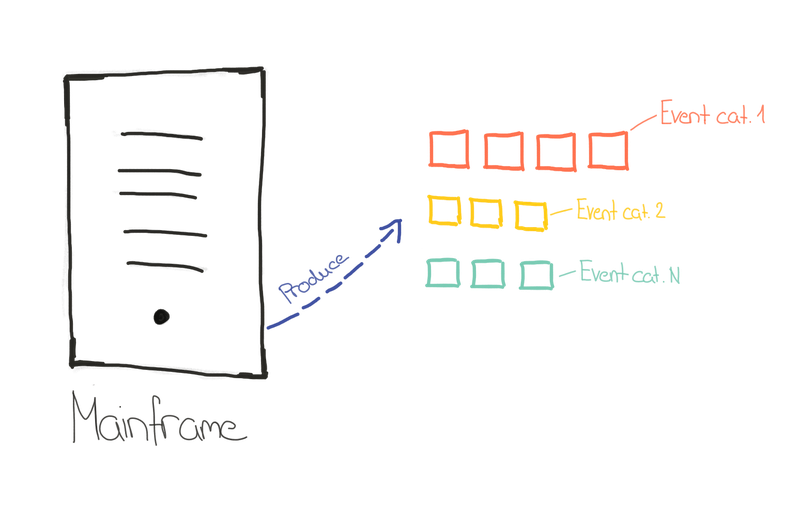
Mainframes zu betreiben ist aufwändig, kostspielig und deren Integration mit anderen Systemen zumeist unflexibel. Kafka kann hierbei Abhilfe schaffen, indem es Daten aus den Mainframes zentral zur Verfügung stellt und somit den Lesezugriff der Daten erleichtert. Dies kann einiges an Kosten sparen.
Grundsätzlich kann man sagen, dass sowohl die Stammdaten Integration als auch das Mainframe Offloading dafür sorgen, dass Daten und gegebenenfalls auch Services rund um die Uhr verfügbar sind, weil die dahinter liegenden Applikationen mit Kafka entkoppelt sind. Die Daten werden während einer möglichen Downtime in Kafka zwischengespeichert und sind somit zumindest lesend verfügbar. Sobald die dahinter liegende Applikation erneut verfügbar ist, können die Daten wieder synchronisiert werden.
Zusammen kombiniert, führen Mainframe Offloading und Stammdaten Integration im besten Falle dazu, dass man die Funktionalität aus Legacy Applikationen Schritt für Schritt ablösen kann.
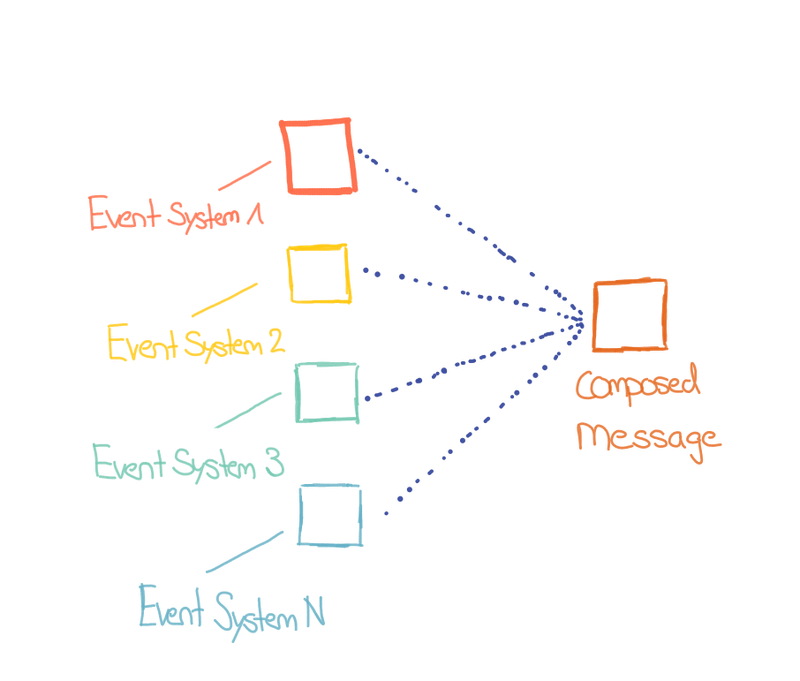
Kafka eignet sich hervorragend als Technologie um sowohl fachlich als auch technologisch belastbare Audit Trails zu erstellen. Applikationen, Sensoren, Interaktionen, Infrastruktur Komponenten, Datenbanken, etc. können sehr feingranulare, häufige und spezifische Events an ein Audit Topic in Kafka senden.
Kafka stellt technisch die Performance zur Verfügung, um dies auf breiter Front zu ermöglichen. Man stelle sich das Monitoring aller Applikationen und die Zugriffe auf jegliche Daten im Unternehmen vor. Durch die Eigenschaften von Kafka ist gegeben, dass der Audit Trail auch den fachlichen Anforderungen genügen kann. Die Reihenfolge der Ereignisse bleibt erhalten. Die Daten stehen fast unmittelbar zur Verfügung. Die Anbindung an weiterführende Gefässe ist nahtlos möglich, z.B. Speicherung in long-term Storage wie Hadoop, Stream Processing Frameworks wie Spark oder Flink, oder anderen Monitoring & Alerting Frameworks wie Prometheus, Grafana, Kibana, Splunk, etc.
In Zeiten zunehmender Regularien und Interkonnektivität von unzähligen Services und Geräten ist nachvollziehbares Auditing unabdingbar. Mit Kafka steht nun eine Technologie bereit, die die notwendigen technischen Anforderungen erfüllt.
Audit Trail

Kafka stellt eine nutzbringende Technologie dar, die sich bereits in zahlreichen Anwendungsfällen in unterschiedlichsten Branchen bewährt hat. Nebst der Umsetzung flexibler und zukunftsorientierter Architekturen und Kosteneinsparungen, hilft es vor allem mehr Flexibilität und Agilität in die Organisation rein zu bringen. Dieses Nutzenversprechen gilt es jedoch, wie bei jeder Technologie, auf den Anwendungsfall abgestimmt, richtig zu realisieren.