
Andreas Schneider
IT Architect
Erfolgreiches Machine Learning (ML) setzt voraus, dass wir den Lebenszyklus von ML-Anwendungen kennen. Deshalb bilden ihn alle grossen Hyperscaler ab.
Autor: Andreas Schneider
In diesem Artikel stellen wir den ML-Lebenszyklus von Microsoft Azure ML vor.
Azure bietet eine Plattform, um Machine-Learning-Modelle zu entwickeln, trainieren, validieren und bereitzustellen. Azure ML unterstützt die Versionierung von Modellen und Daten und erlaubt das Aufzeichnen von Metriken und Ergebnissen. Die Entstehung von ML-Modellen kann also nachvollzogen und die Modelle selbst können reproduziert werden. Wir können mit Azure ML beschleunigt und vereinfacht ML Pipelines unter der Berücksichtigung von Best Practices zusammenbauen.
Speziell für ML kann die Cloud mit der Skalierung der Ressourcen beim Training von Modellen punkten. Dies beschleunigt die Produktentwicklung und verkürzt die Time To Market.
Der typische ML-Lebenszyklus reicht von der Entstehung der Modelle bis zu deren Betrieb (Abbildung 1). Er beinhaltet das Sammeln von Daten, das Trainieren, die Evaluation, das Deployment und die Überwachung während dem Betrieb von Modellen. Azure ML deckt alle diese Bereiche ab.
Wir beginnen mit dem Einlesen der Daten und starten mit einer explorativen Phase. Wir schauen die Daten genauer an und testen erste Modelle.
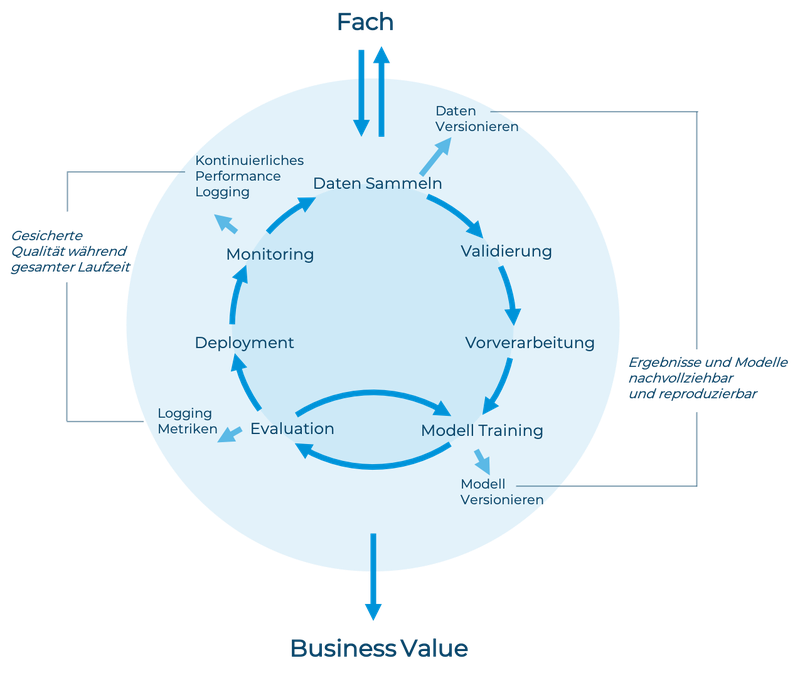
Azure ML löst das Problem, wie die Daten in der Cloud effizient vom Speicherort zu den Recheninstanzen kommen. Als Entwickler müssen wir lediglich die Daten nach Azure ML einspeisen. Innerhalb Azure ML gibt es zwei Konzepte für den Datenzugriff:
○ Tabellarisch: Für Daten in Tabellen.
○ Dateien: Für weniger strukturierte Daten. Der Zugriff funktioniert wie über ein gewöhnliches Dateisystem.
Ein Dataset kann auf Recheninstanzen eingelesen werden, zum Beispiel innerhalb eines Experiments. Werden mehrere Verarbeitungsschritte benötigt, bietet es sich an, Pipelines zu verwenden. Da Pipelines sich die Resultate der Zwischenschritte merken, müssen also nicht alle Schritte neu ausgeführt werden, wenn nur ein Teil geändert wurde.
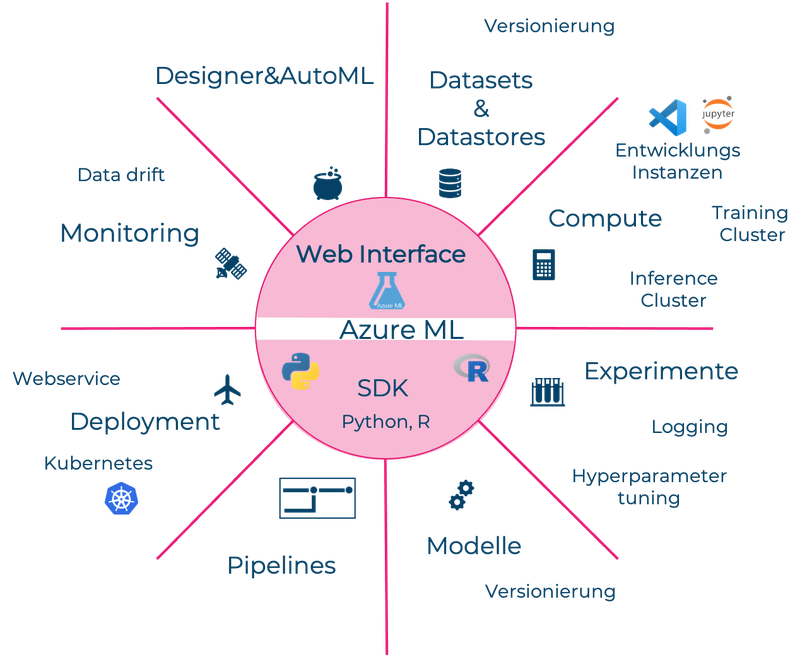
In Azure ML werden Modelle innerhalb von Experimenten erstellt. Modelle und ihre entsprechenden Qualitätsmetriken werden für jeden Experimentdurchlauf von Azure ML getrackt. Die Resultate können im Webinterface eingesehen oder über die API abgerufen werden (Abbildung 2). Wir können verschiedene Durchläufe überprüfen und dann diejenigen Modelle und Parameter auswählen, welche die besten Resultate liefern. Wir wechseln also zwischen Modelle trainieren und evaluieren, bis wir zufrieden sind. Das Training findet auf speziellen Azure Trainingsclustern statt, deren Grösse wir nach Bedarf anpassen können.
Für das Training verwenden wir lediglich die Trainingsdaten. Wir prüfen die Leistung des ausgewählten Modells vor dem Deployment auf einem Test-Dataset, das wir während dem Training nicht verwendet haben. Dieser Datensatz sollte möglichst nah an den aktuellen produktiven Daten sein. Sind die Schritte von den Daten bis zum Modell als Pipeline implementiert, können wir die Modelle einfach reproduzieren oder mit neuen Daten trainieren.
Haben wir ein Modell ausgewählt, können wir es mit Azure ML relativ einfach als Webservice der Allgemeinheit zur Verfügung stellen. Der Service kann von anderen Applikationen als gesicherter REST Endpoint verwendet werden. Dafür gibt es auf Azure spezielle Inference Cluster, deren Kapazität sich an die Nachfrage anpasst. Wir müssen lediglich ein Inference Script erstellen, welches die Eingabe des Webservices und das gespeicherte Modell verwendet und eine Modellvorhersage zurückgibt.
Nach dem Deployment geht es darum die Qualität der Ergebnisse sicherzustellen, welche ein Modell liefert. Es ist gut möglich, dass sich die Eingabedaten allmählich von den Daten für das Modell-Training unterscheiden. Deshalb speichern wir die Eingabedaten und die Ergebnisse des Webservice, um sie mit dem Trainingsset zu vergleichen. Finden wir eine Abweichung zwischen den produktiven Daten und den Trainingsdaten, stellen wir einen «data drift» fest. Diese Verschiebung überwacht Azure ML automatisch und meldet sie, damit wir gegebenenfalls eingreifen können.
Die gesammelten produktiven Daten, können wir für künftiges Modell-Training verwenden, um die Modelle stetig zu verbessern. Da wir die ganzen Verarbeitungsschritte von den Daten bis zum Modell als Pipeline implementiert haben, können wir automatisch ein neues Modell auf neuen Daten trainieren und wieder als Webservice bereitstellen.
Azure ML ist bereit für den Einsatz in Unternehmen. Governance-Themen wie Zugriffsberechtigungen auf Daten und Modelle und die Nachvollziehbarkeit sind geregelt. Es gibt Konzepte für verantwortungsvolles ML, welche Themen wie Biases, Fairness und Erklärbarkeit behandeln. Für eine unternehmensweite Bestandesaufnahme von ML-Potentialen gibt es ein Tool zur Katalogisierung von Datenquellen - einen Datenkatalog. Die Entwickler können ihre bestehenden ML Skills in der Cloud weiterverwenden, da gängige ML Frameworks und Libraries unterstützt werden.
Microsoft bietet mit Azure ML ein ausgeklügeltes System für skalierbares Machine Learning in der Cloud, welches den ganzen ML-Lebenszyklus abdeckt. Damit ist es möglich, schnell und nachvollziehbar reproduzierbare Modelle zu entwickeln, welche qualitativ hochwertige Ergebnisse liefern.