
Gerald Reif
Principal Architect, Director
Blog series | From Data to Business Value with Data Mesh | #3
Authors: Gerald Reif & Yu Li
In our last blog post, we introduced the four principles that underpin a data mesh. These principles are technology-agnostic and do not specify how a data mesh must be implemented. This has the advantage that a data mesh can be implemented on many platforms and with a wide variety of service components. However, this flexibility carries the risk that the technical implementation violates the underlying principles. In this blog post, we derive the requirements that arise from the four data mesh principles and show how these requirements can be implemented technically.
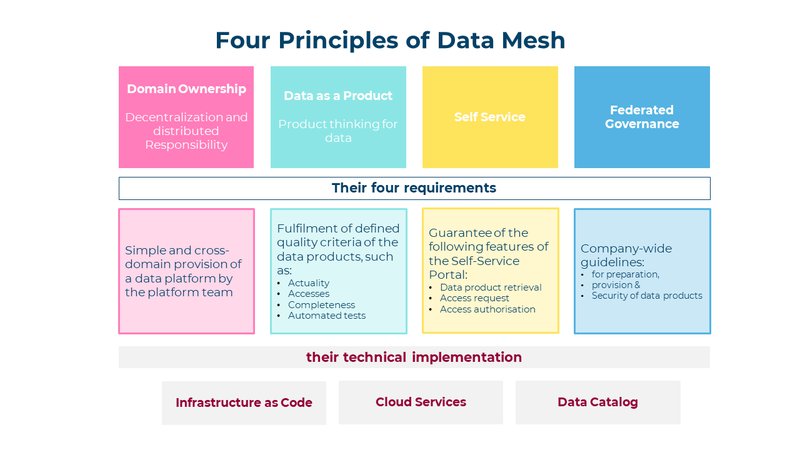
Responsibility for the data is assumed by the domains, i.e. by the individual departments in the company. In a data mesh, there is one instance of a data platform per domain. This results in the requirement that a platform team must be able to provide an instance of the data platform to the domains with little effort.
Analogous to other products, a data product must also meet certain quality criteria. To make this possible, it must be clear to what extent and with what timeliness a data set is provided and via which interface the data can be accessed. Furthermore, the completeness and correctness of the data must be continuously checked by automated tests.
Why are defined quality criteria so essential? Knowing the quality criteria creates trust in a data set and allows business-critical decisions to be made based on data.
In order for a domain (department) to be able to prepare its data products in a data mesh as easily as possible, each domain team should be provided with an instance of the data platform via self-service. In addition, data products (data sets) should be made available for reuse, provided that the corresponding data owner agrees to this.
In a self-service portal for data products, the following must be possible:
Even though the domains in a data mesh are responsible for the preparation, provision and quality of their data products, it must be ensured that company-wide guidelines are adhered to in each domain. These guidelines should address and regulate the following points:
In the previous section, we looked at the requirements that result from the four data mesh principles. Now the question arises as to how these requirements can be implemented in a data platform.
In this section, we present three technologies that enable the efficient construction of a data mesh.
In a data mesh, the platform team must provide each domain with an instance of the data platform. Each of these instances must meet the functional specifications for data storage and analytics as well as the core specifications for security, audit and governance. To ensure that each platform meets the specifications for each domain, platform deployment must be automated. Through Infrastructure as Code, the services that make up a data platform are described and configured in a formal language. The deployment tool processes this formal description and thus ensures that the defined specifications are met in each domain and in each staging environment (Dev, Test, Prod). The formal description of the platform via laC guarantees that no manual configuration errors occur in any environment. IaC is also the basis for providing a data platform via self-service for a domain team.
A data platform consists of a number of components that enable data storage and processing, access protection, monitoring and auditing. All these components need to be managed via end-to-end user management. For this purpose, all large hyperscalers offer cloud service solutions that optimally fulfil the required requirements, can be integrated and regulate comprehensive access protection. The cloud services can also be deployed via laC and thus represent the ideal basis for implementing a data mesh.
In a data mesh, responsibility for the data lies with the individual domain teams. Their responsibilities include:
In order to be able to make company-wide data-based decisions, data processing must not end at the domain boundaries. Other domains must be aware of the existence of high-quality data products, enrich this data with their own data and thereby create higher-quality analyses and data products.
A data catalogue performs exactly this task in a data mesh. Each domain promotes and manages its data products in the company-wide data catalogue. This describes each data product using the following information, among other things:
If another team has identified a data product in which it is interested in this way, access to the data can be requested via the data catalogue. If the data owner agrees to this use, the data catalogue releases the corresponding authorisations.
The data catalogue thus represents the central interface for ensuring the cross-domain reuse of data products.
In this blog post, the requirements arising from the 4 data mesh principles were discussed and the technological approaches were presented with which these requirements can be implemented preferentially.
In summary, the following can be said:
In part 4 of this blog series, we will report on concrete experiences our customers have had with Data Mesh.
#1 Blog series Data Mesh: Blog 1
#2 Blog series Data Mesh: Blog 2
#3 Blog series Data Mesh: Blog 3
#4 Blogserie Data Mesh: Blog 4
We look forward to hearing from you
