
Filka Auer
Principal Architect
Es gibt zwei Skalierungs-Strategien: Scale-up und Scale-out. Wie unterscheiden sich diese und wann wird welche Variante in der IT eingesetzt? Zwei Beispiele.
«Neun Frauen können ein Kind auch nicht in einem Monat zur Welt bringen»
Autorin: Filka Auer
Der Begriff «Skalierbarkeit» ist im IT-Bereich in aller Munde und wird oft als Grundanforderung formuliert. Aber wann ist ein skalierbares System tatsächlich notwendig und wie funktioniert die Skalierung überhaupt? Gibt es dafür ein Universalrezept?
In der IT bedeutet Skalierbarkeit die Fähigkeit eines Systems, seine Gesamtleistung unter erhöhter Last (mehr Daten, mehr Nutzeranfragen) proportional zu steigern, durch Hinzufügen von Ressourcen (typischerweise Hardware). Optimal skaliert ein System dann, wenn die Leistung mit den hinzugefügten Ressourcen linear ansteigt – das ist in der Praxis jedoch nur mit einer speziell darauf abgestimmten Software- und Hardwarearchitektur zu erreichen.
Schauen wir uns zwei konkrete Situationen an, die nach einer skalierenden Lösung verlangen:
Wie können die beiden Unternehmen ihre Systeme am besten skalieren? Und was entscheidet darüber, wie eine gut skalierende Lösung aussehen muss?
Es lassen sich generell zwei Arten von Skalierungsstrategien unterscheiden: Die horizontale Skalierung (scaling-out) und die vertikale Skalierung (scaling-up).
Scaling-up bezeichnet das Hinzufügen von Ressourcen innerhalb einer logischen Einheit.
Beispiele hierfür sind: Das Einsetzen eines leistungsfähigeren Speichers (z.B. Flash Storage), das Hinzufügen von CPUs oder GPUs zu einem existierenden Server, oder das Aufrüstung des Arbeitsspeichers.
Die Software, um Multi-Core-Architekturen im Kontext einer einzigen Anwendung zu nutzen wird in der Regel durch Parallel-Programmierung realisiert, z.B. durch Multithreading und Interprozesskommunikation. Hierfür stehen verschiedene Libraries und Compiler-Erweiterungen zur Verfügung, wie z.B. OpenMP, CUDA und OpenCL, etc.
Typische Anwendungsbeispiele vertikaler Skalierung sind Echtzeit-Anwendungen für Visualisierung oder Bildverarbeitung wie z.B. Virtual Reality, Computerspiele, Sortieranlagen oder Inline-Qualitätsprüfung am Produktionsband. Das Berechnungsergebnis z.B. bei interaktiven Anwendungen muss häufig in Echtzeit feststehen und wird in der Regel aus Teilergebnissen zusammengesetzt, die auch voneinander abhängig sein können. Die Teilergebnisse werden zur optimalen Skalierung auf eigenen Threads berechnet, was häufig eine Synchronisierung von Daten zwischen mehreren Threads verlangt. Diese brauchen deshalb alle Zugriff auf den gleichen, schnellen Speicher (z.B. den Hauptspeicher oder den GPU-Speicher).
Scaling-out bezeichnet das Hinzufügen mehrerer logischer Ressourcen-Einheiten (Nodes) zu einem System, die miteinander verbunden werden. Mit dem Ziel, dass sie wie eine logische leistungsstarke Einheit funktionieren.
Beispiele hierfür sind: Das Erhöhen der Anzahl verfügbaren Server eines Rechenzentrums (wobei z.B. ein Server als Proxy oder Lastverteiler dient), oder Cloud-Architekturen, die über Cluster mit virtuellen Nodes verfügen.
Für den Betrieb eines solchen verteilten Systems sind spezielle Softwaretools für verteilte Programmierung notwendig. Typische Implementierungsmuster hierfür sind MapReduce, Worker/Master Schema oderBlackBoard.
Eingesetzt wird die horizontale Skalierung üblicherweise für«Big Data»-Anwendungen, die riesige Datenmengen in Clouds speichern und auswerten um z.B. Echtzeit-Statistiken in sozialen Medien zu berechnen, Echtzeitanfragen von Benutzern zu bedienen (Google Suche), Ausbrüche von Krankheiten vorherzusagen, oder um Konsumverhalten zu analysieren.
Die elementaren Berechnungen innerhalb verteilter Anwendungen weisen in der Regel eine geringe bis mittlere Komplexität auf. Die darin produzierten Teilergebnisse werden in Volumen und Dimensionen bereits stark reduziert, bevor sie zu einem vollständigen Ergebnis kombiniert werden. Ein Beispiel hierfür ist die Berechnung der Anzahl von Erwähnungen relevanter Begriffe in sozialen Medien, um Trends zu bestimmen.
Beide Skalierungsarten habe ihre Vor- und Nachteile.
Bedeutsame Vorteile der vertikalen Skalierung sind die einfachere Realisierung und Unterhaltung. Sowohl Arbeitsspeicher als auch Datenspeicher bleiben in einer logischen Einheit. Das macht den Datenaustausch durch die Übergabe von Speicherreferenzen und durch Caches in vielen Fällen sehr effizient. Auch müssen an der Software im Allgemeinen keine Änderungen vorgenommen werden, um vom Leistungszuwachs zu profitieren.
Die vertikale Skalierung ist jedoch durch die maximale Hardwareausstattung des Rechners nach oben beschränkt. So ist es z.B. nicht möglich, beliebig viel Arbeitsspeicher in einen Rechner einzubauen. Leistungsfähigere Hardware wird außerdem schnell sehr teuer.
Das Hinzufügen von Standardhardware zu einem Cluster ist wesentlich günstiger und nicht auf die Kapazität einer einzelnen Einheit beschränkt. Das Fehlen eines (schnellen) gemeinsamen Speichers bei der horizontalen Skalierung erschwert jedoch die Kommunikation und den Datenaustausch innerhalb des Clusters und macht die gemeinsame Nutzung, Weitergabe und Aktualisierung von Daten wesentlich komplexer. Nur mit speziellen Softwarearchitekturen und Maintenance-Tools kann dies effizient und fehlerrobust implementiert werden.
Nein, in vielen Fällen ist das durch das vorliegende Skalierungsproblem bereits vorbestimmt. Mit Blick auf die beiden Firmen, Sale Corp. und Sauber AG, lässt sich dies genauer begründen:
Bei der Entscheidung, ob Scale-out oder Scale-up, oder ob gar beide Ansätze gleichzeitig erforderlich sind, spielen die Art der jeweiligen Problemstellung und die Eigenschaften der Daten eine entscheidende Rolle:
Wird eine Echtzeit-Antwort vom System erwartet und ist das endgültige Berechnungsergebnis nur mittels häufiger Synchronisation von Zwischenergebnissen zu bestimmen, ist eine vertikale Skalierung generell von Vorteil. Handelt es sich um sehr viele kleine Datensätze, die sich gut partitionieren lassen, kann hingegen die horizontale Skalierung große Vorteile bieten. Es müssen aber erstmal aufwendige Software-Anpassungen vorgenommen werden, um überhaupt von den zusätzlichen Rechnern profitieren zu können.
Im speziellen Bereich der numerischen Simulation müssen häufig sowohl viele als auch sehr große Datensätze verarbeitet werden. In diesem Fall wird eine Skalierung sowohl in die vertikale, als auch in die horizontale Richtung notwendig. Diese Aufgabe bewältigen üblicherweise Supercomputer.
In der nachfolgenden Tabelle sind die beiden Skalierungsstrategien und üblichen Use-cases im Vergleich dargestellt.
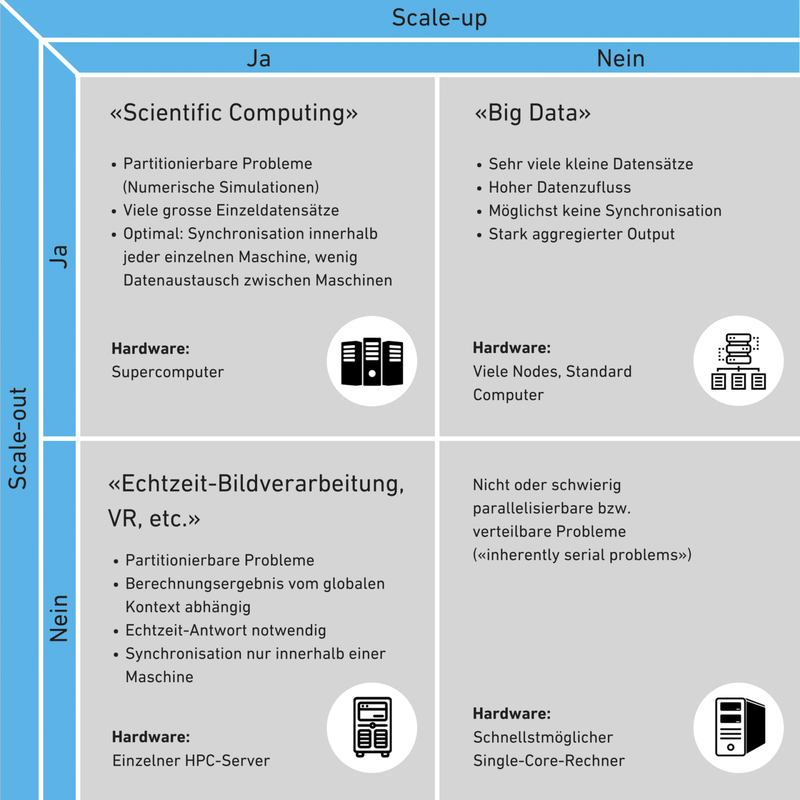
Skalierbarkeit bezeichnet die Fähigkeit eines Systems zu wachsen, um steigende Anforderungen zu bewältigen. Wie die konkrete Lösung dafür aussieht, kann sehr unterschiedlich sein. An den obigen Beispielen zeigt sich, dass die Entscheidung zwischen Scaling-up und Scaling-out keineswegs trivial und sehr stark vom Analyseproblem, den Daten und von den geforderten Antwortzeiten abhängig ist. Entscheidend sind aber ebenso die Kosten für die jeweilige Lösung. Eine neue Applikation, die künftig substanzielle Leistungssteigerungen erlauben soll, wird am besten so gestaltet, dass sie Scale-out unterstützt.
Für die beiden Firmen, Sale Corp. und Sauber AG, ist es wichtig, eine für sie passende Skalierungsstrategie zu finden um ein gutes Verhältnis von Kosten zur Leistungssteigerung zu erzielen. Für die Sale Corp. stellt sich die Scaling-Out-Strategie als am günstigsten heraus; für die Sauber AG hingegen die Scaling-Up-Strategie.