

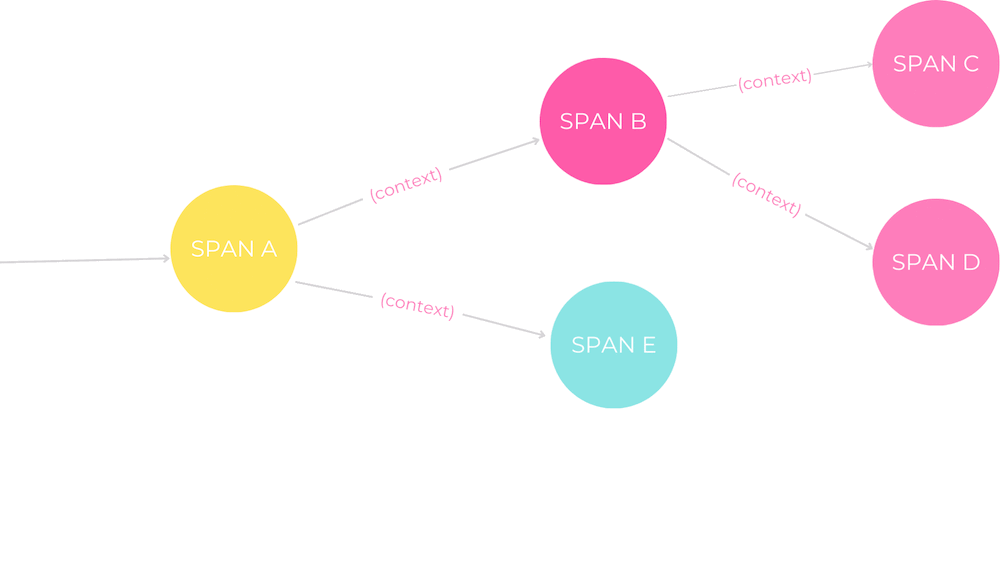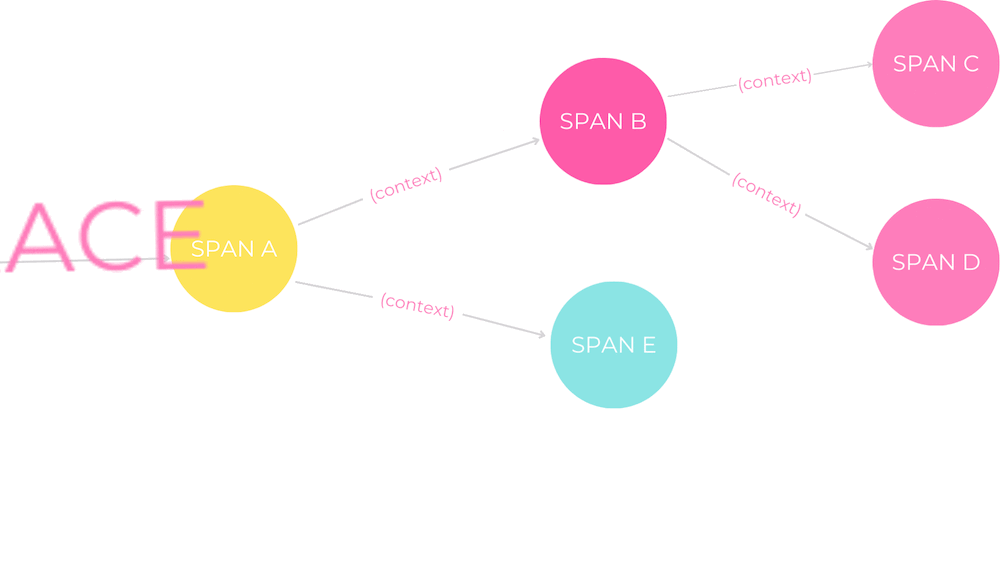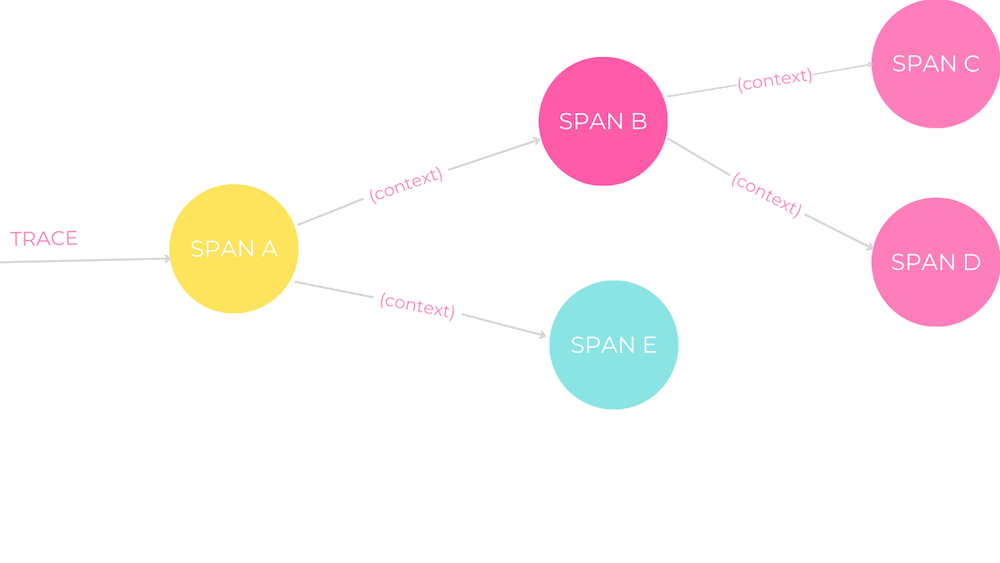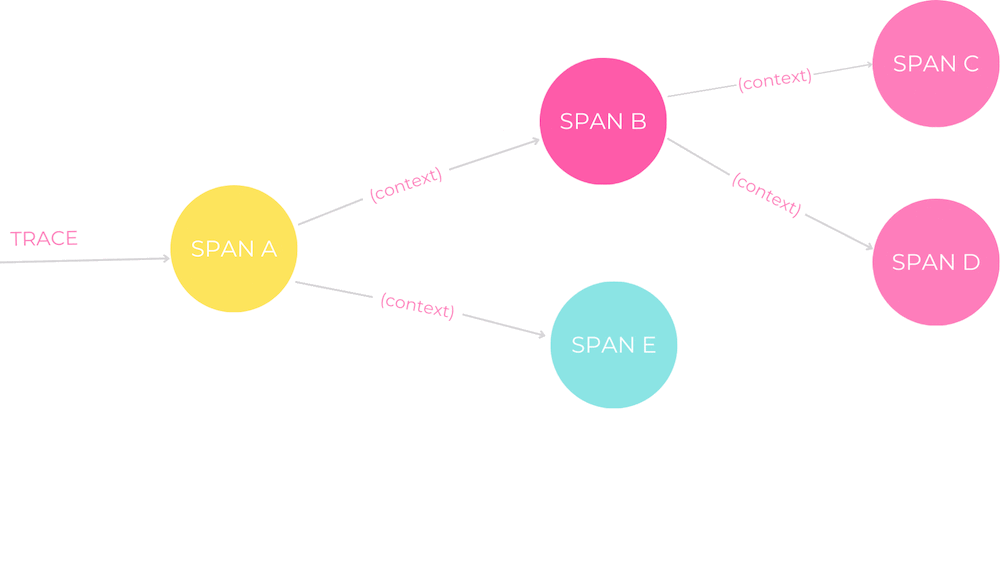
“Die verteilte Rückverfolgung ermöglicht einen beispiellosen Einblick in unsere verteilten Systeme”
Yuri Shkuro SWE Uber Technologies, Autor "Mastering Distributed Tracing", Entwickler von Jaeger & Co-Gründer des OpenTelemetry CNCF Projekts




“Die verteilte Rückverfolgung ermöglicht einen beispiellosen Einblick in unsere verteilten Systeme”

