Bild 1: Darstellung von Retrieval Augmented Generation (Abbildung von RDE und PRI)
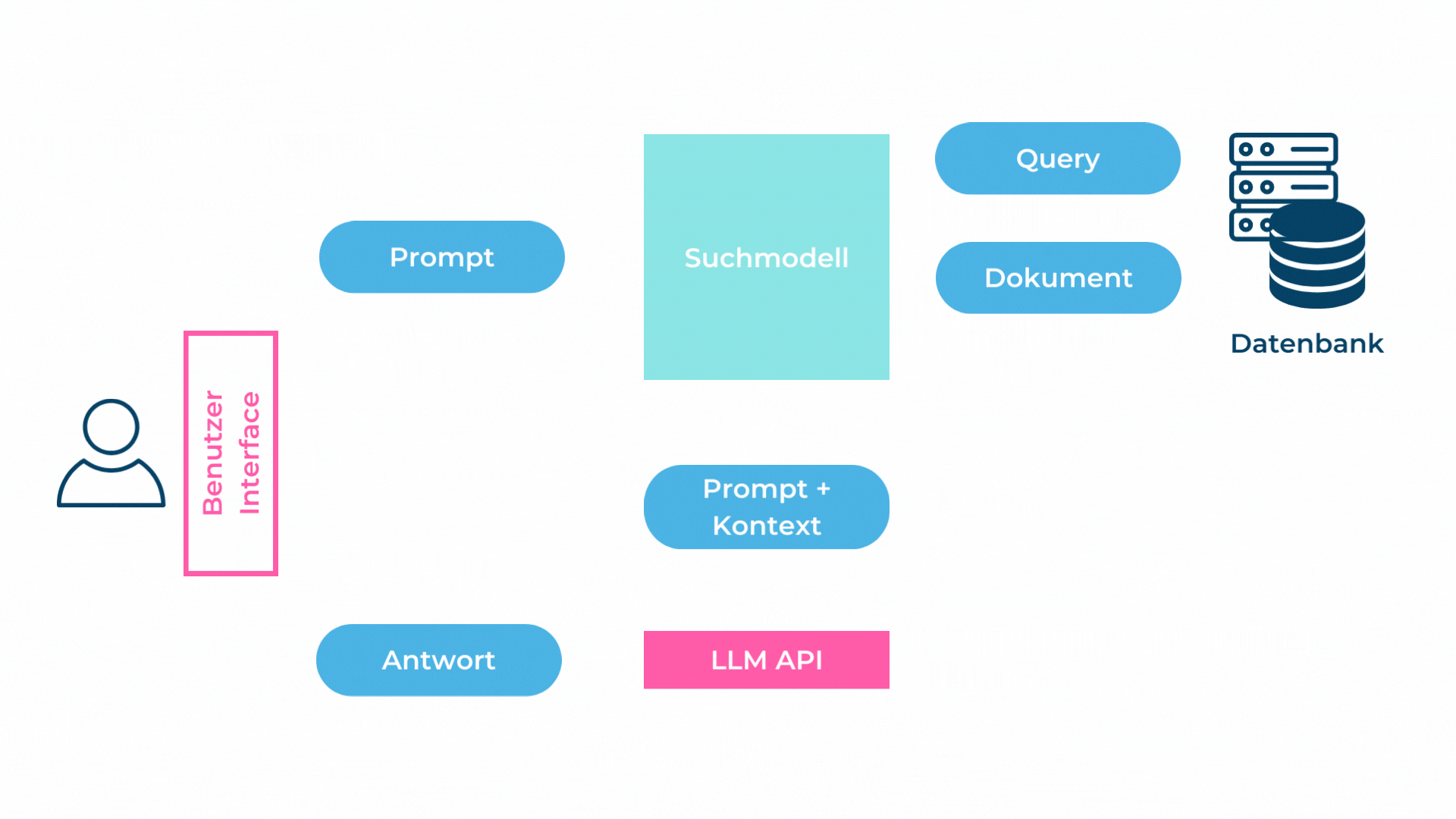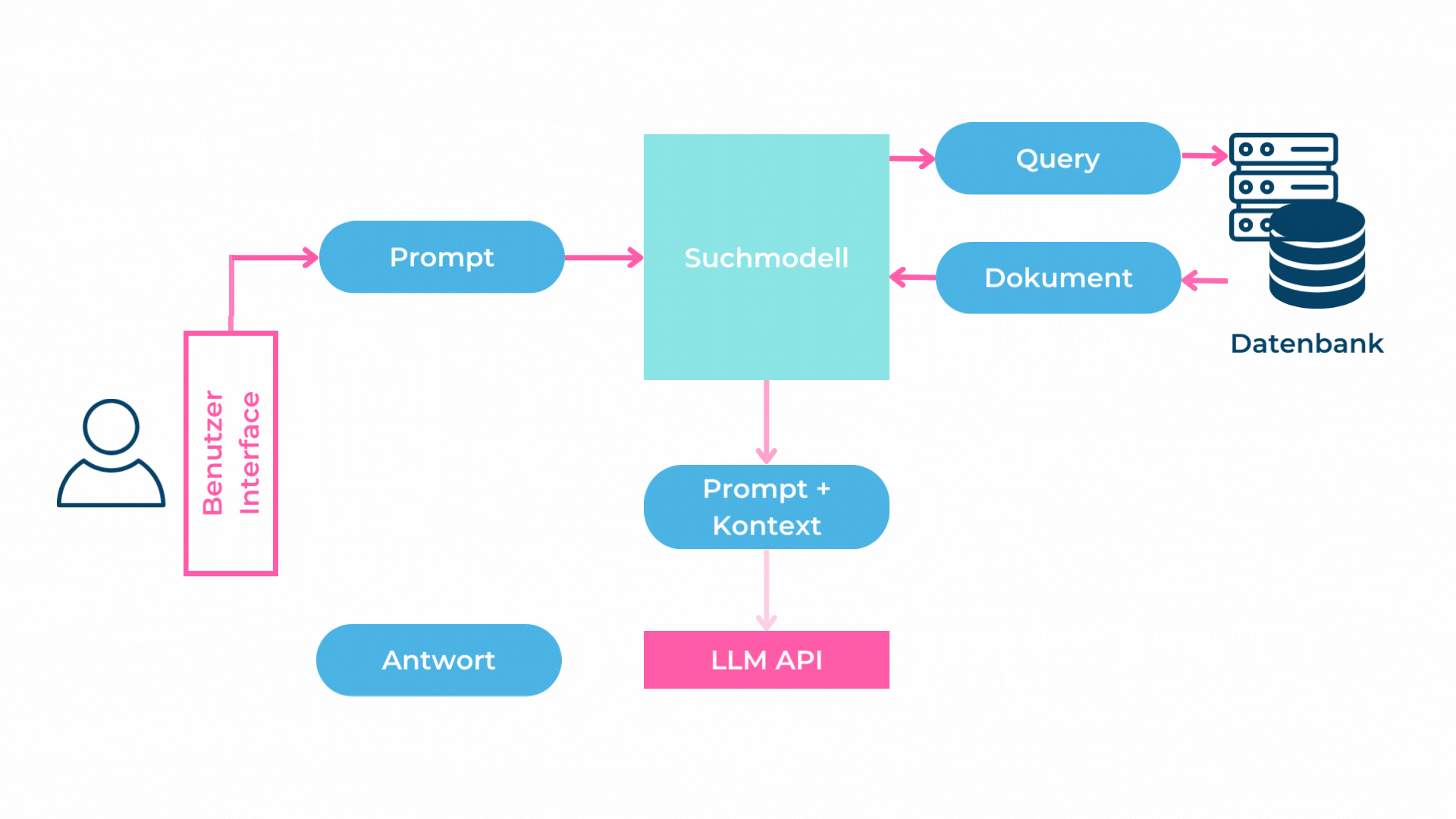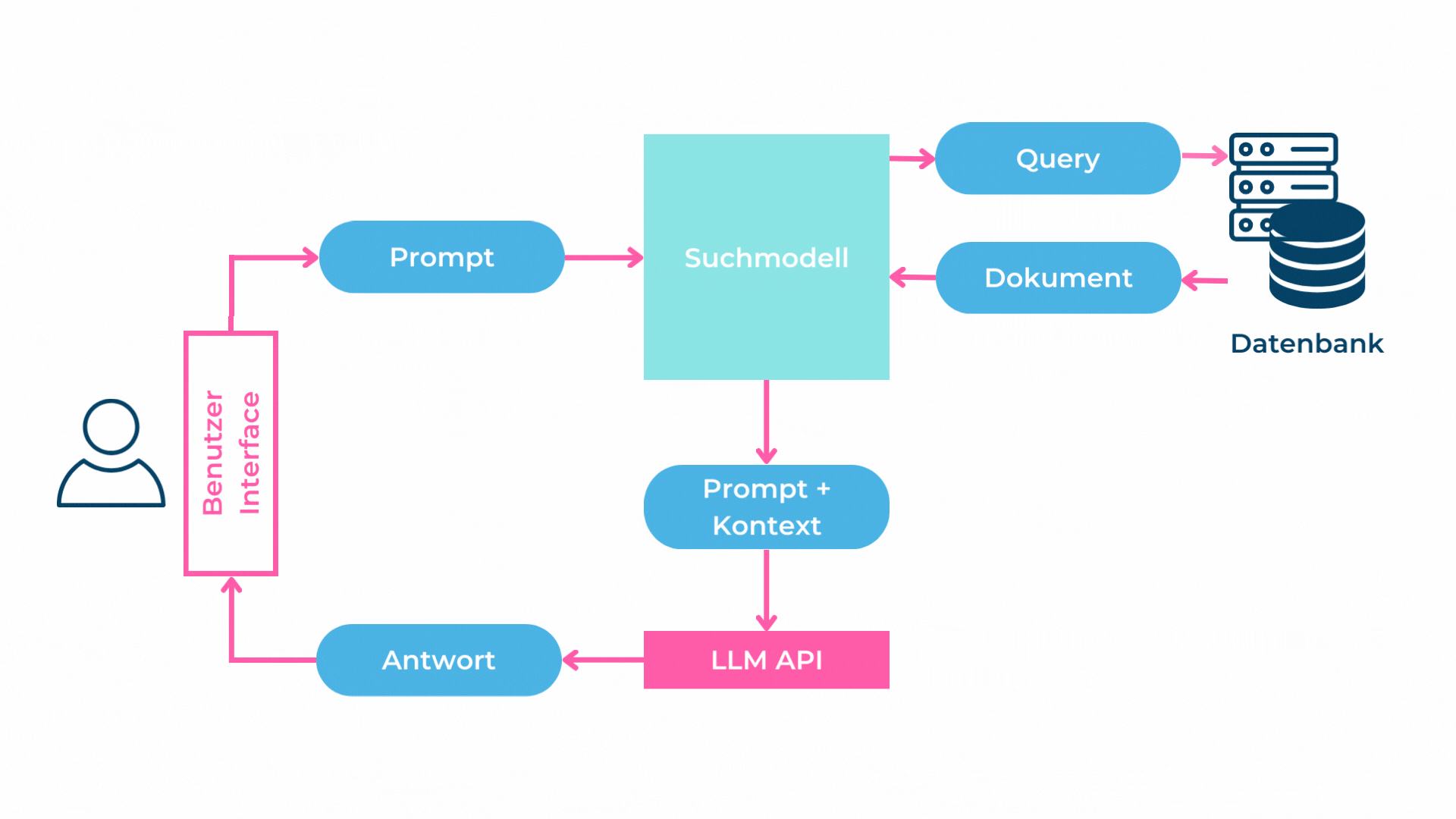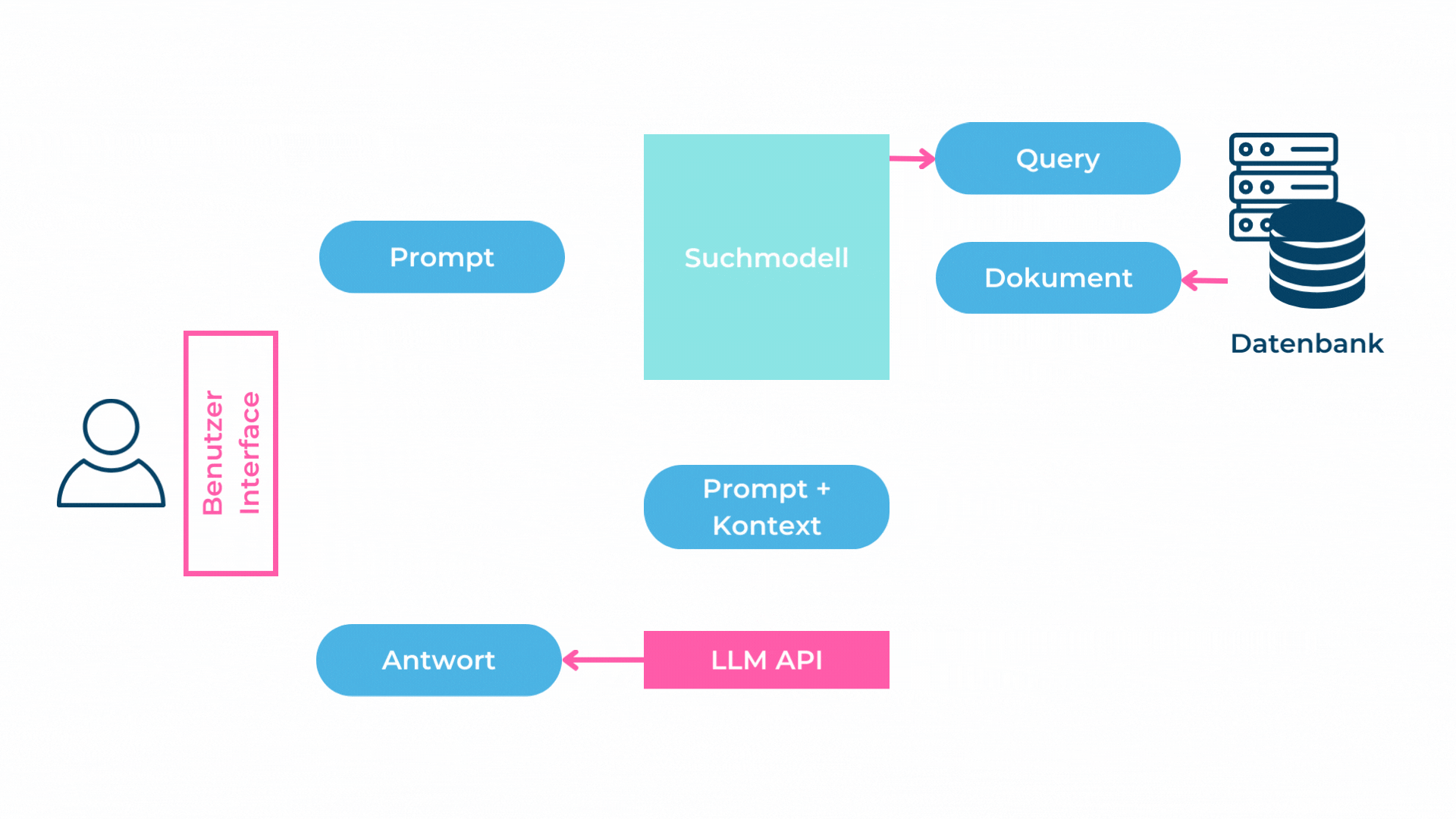 Bild 1: Darstellung von Retrieval Augmented Generation (Abbildung von RDE und PRI)
Bild 1: Darstellung von Retrieval Augmented Generation (Abbildung von RDE und PRI)