Data Chunking
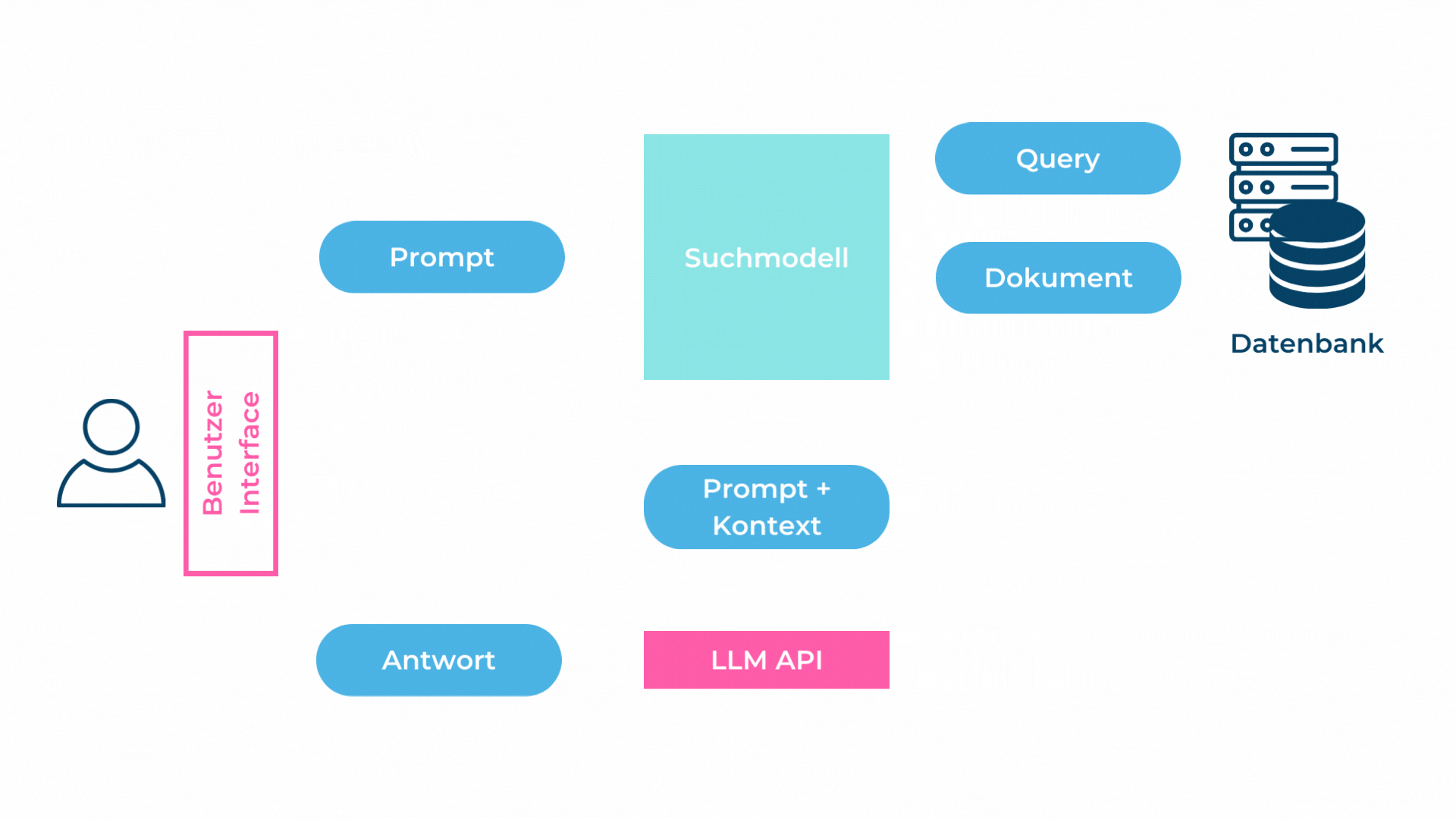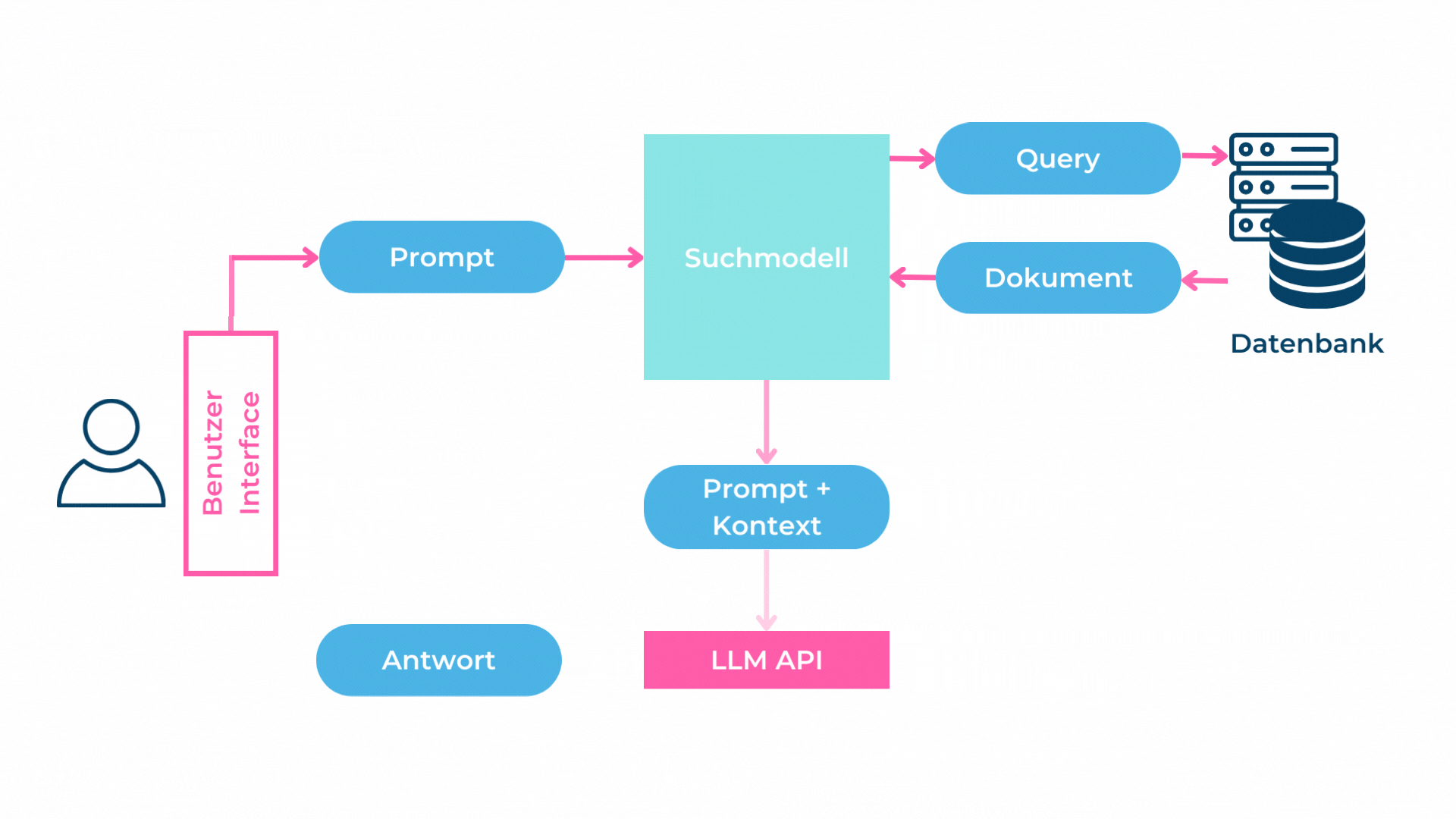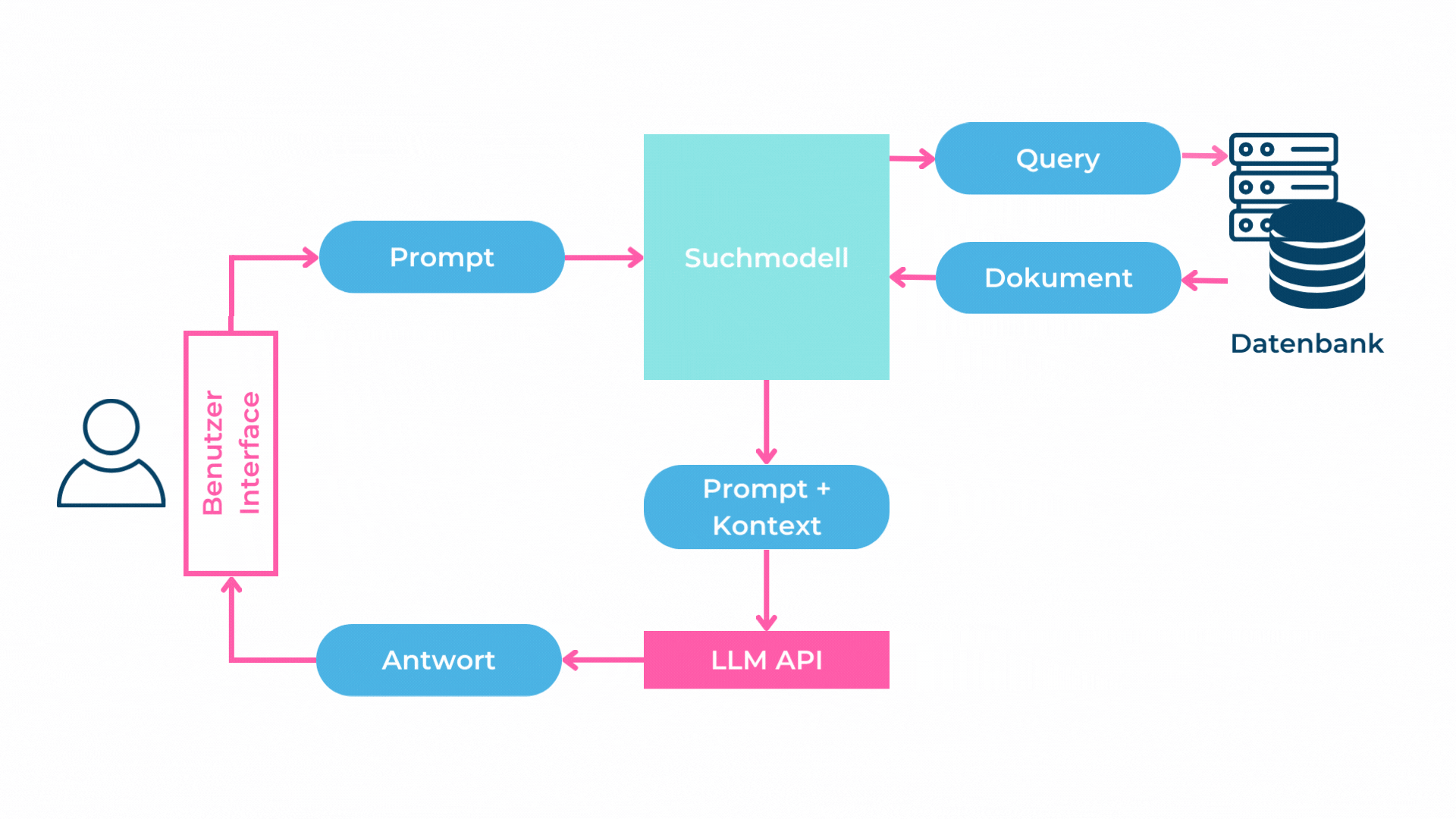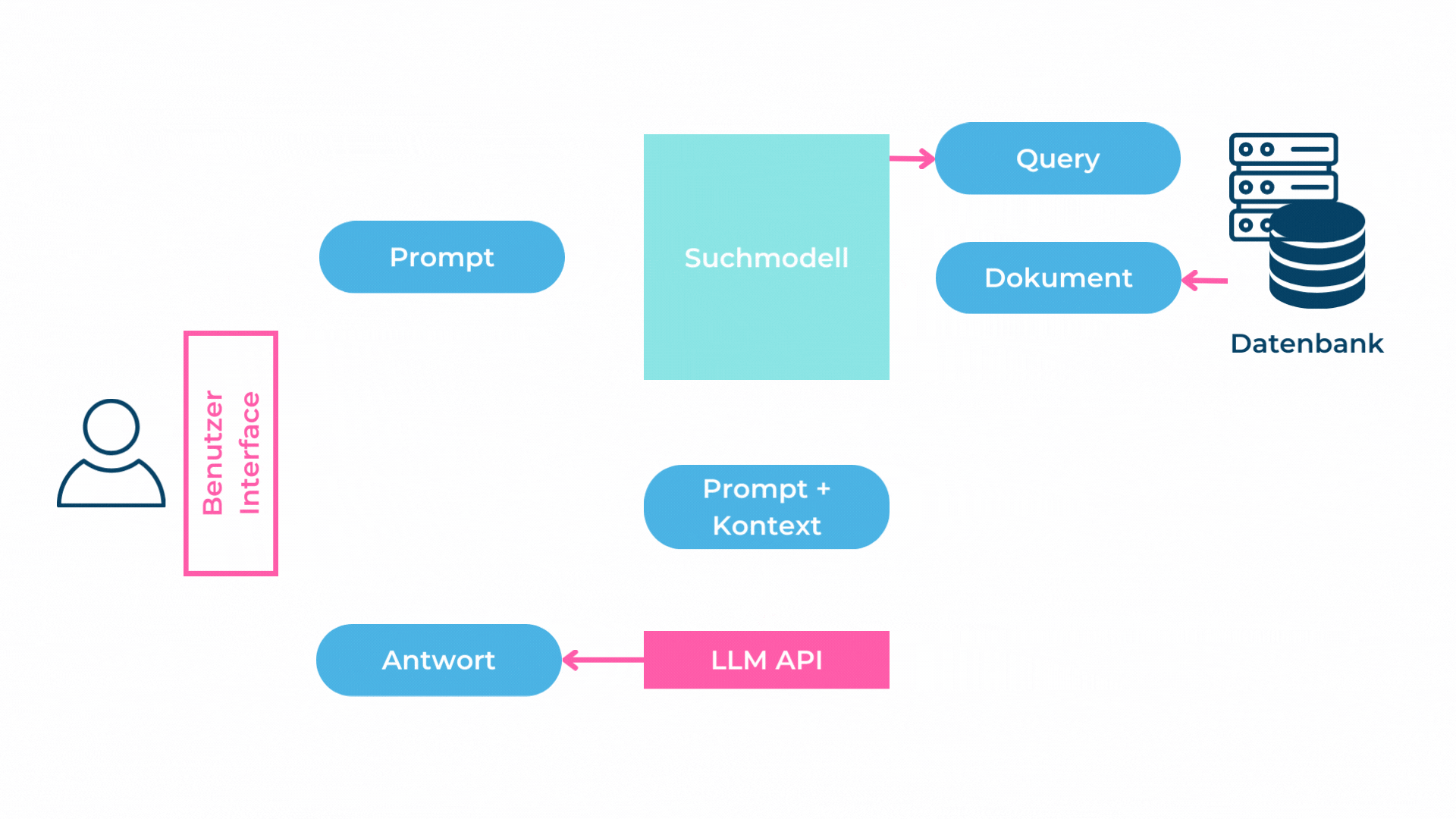
Das Zerlegen eines Textdokumentes in kleinere Teile (Chunks) hat den Nachteil, dass Zusammenhänge und Beziehungen im Text verloren gehen. Beim RAG-Pattern werden nur die Top-K Chunks dem LLM im Prompt übergeben, weshalb das Sprachmodell Schwierigkeiten haben wird, Fragen, welche genau diese Zusammenhänge voraussetzen, zu beantworten.
Folglich ist das RAG gut in eng gefassten, beschreibenden Fragen ohne grossen Zusammenhang. Beispiel: «Gibt es einen Mitarbeiter mit Java-Kenntnissen?». Bei Fragen über Zusammenhänge, langfristige Zusammenfassungen oder Fragen mit Vollständigkeitsanspruch wie «Kannst du mir eine Liste mit allen Mitarbeitern, welche mind. 3 Jahre C#-Kenntnisse haben, erstellen?» hat das RAG-Pattern Mühe.
Auf der anderen Seite kann man Chunks nicht beliebig gross erstellen. Das Embedding Modell reduziert den Inputtext auf einen Vektor, welcher die semantischen Eigenschaften bestmöglich erhalten soll, jedoch durch die reduzierte Dimension Informationen verliert.
Embedding Modelle sind weniger effektiv bei Texten mit vielen Themen oder mehreren Wendungen, weshalb kürzere Chunks im RAG besser abschneiden.
Ein wichtiger Parameter beim «Fine tuning» des RAG-Pattern ist folglich die Chunkgrösse. Bei einer Analyse von MSFT schnitt eine Grösse von 521 Input Tokens pro Vektor am besten ab.
Neben der Grösse gibt es diverse Strategien, welche die Performance verbessern können. Zum Beispiel kann man den Text in überlappende Chunks einteilen, um das Risiko, Zusammenhänge aufzubrechen, zu reduzieren. Oder man implementiert eine Strategie für Metadaten, welche in der semantischen Suche neben der Vektor-Ähnlichkeit benutzt wird.
Für gewisse Anwendungsfälle lohnt es sich, ein Preprocessing einzelner Daten zu machen. So kann zum Beispiel bei einem Competence Profile jedes Projekt einen Chunk darstellen, welchen man mit den Informationen der Mitarbeiter:innen ergänzt. So kann man den Zusammenhang des Projektes und den Mitarbeiter:innen, der sonst verloren ging, wiederherstellen.
Ein weiterer Ansatz wäre das Generieren einer Zusammenfassung des Textes vor und nach dem aktuellen Chunk, um den Kontext im Dokument nicht zu verlieren.
Wir empfehlen in der Incubate-Phase die Anwendungsfälle auf diverse Preprocessing und Chunking-Strategien zu prüfen, um schnell einen Einblick in die Mögliche Performance zu bekommen.