
David Konatschnig
Principal Architect
Einen Kafka Cluster zu betreiben, galt bis anhin als grosse Herausforderung, da es viel Know-how und Erfahrung voraussetzt.
Dies hat sich mit der Entwicklung von Kubernetes Operatoren geändert. Ein Operator unterstützt dabei durch die Automatisierung von komplexen Arbeitsschritten. Gerade für PoCs (Proof-of-Concept) bietet sich der Einsatz eines Operators an, da man sehr einfach zu einem operativen Cluster kommt und somit schnell Erfahrungen sammeln kann. Die Public Cloud eignet sich dazu ideal als Basis für ein elastisches Setup.
Autor: David Konatschnig
Seit ich vor rund 3 Jahren meinen Blogpost Apache Kafka und was es mit dem Hype auf sich hat geschrieben habe, ist vieles passiert in der Welt des Stream Processings. Apache Kafka ist definitiv kein Hype mehr, dies belegen eindrückliche Zahlen: Gemäss Confluent haben
Nicht zuletzt dürfte einer der Hauptgründe die breite Einsatzmöglichkeit für unterschiedlichste Use Cases sein. Mario Maric beschreibt einige davon in seinem Blogpost.
Die grosse Popularität hat auch eine stark wachsende Community gebildet, welche intensiv an der Entwicklung von Apache Kafka sowie an Tools und Produkten im Kafka-Ökosystem arbeitet.
Doch das Aufsetzen und Betreiben eines Kafka Clusters sowie dem Ökosystem (Kafka Connect, Schema Registry, KSQL, ...) stellt IT-Abteilungen vor Herausforderungen. Es bedingt sehr viel technisches Know-How und ein entsprechend aufgestelltes Team.
Es gibt unterschiedliche Ansätze, wie Kafka Cluster betrieben werden können:
In diesem Blog möchte ich aufzeigen, was man braucht, um in wenigen Schritten einen self-managed Kafka Cluster mit Hilfe eines Operators in der Public Cloud zu deployen.
Container sind in der heutigen cloud-nativen Welt nicht mehr wegzudenken. Dies gilt auch für Kafka. Obwohl Kafka auch auf Bare-metal und VMs deployed werden kann, ist der de-facto Standard heute container-basiert mit einem Orchestrator wie Kubernetes. Nebst der einfachen Skalierung, die Kubernetes mitsichbringt, gibt es viele weitere Vorteile. Einer davon sind die Kubernetes Operatoren.
Ein Kubernetes Operator ist nichts anderes als eine Erweiterung für Kubernetes, welche einen gewünschten Zustand auf einem Cluster herstellt. Vereinfacht gesagt wird ein Zustand definiert, also was auf dem Cluster deployed werden soll (z.B. ein Kafka Deployment mit 3 Brokern). Der Operator interpretiert diesen Zustand und führt entsprechende Operationen aus, um diesen zu erreichen, und prüft permanent, dass dieser Zustand so bleibt. Gerade bei einem komplexen Deployment wie Kafka, wo viele Konfigurationen zusammenspielen müssen, welche üblicherweise “von Hand” gepflegt werden, ist ein Operator eine enorme Unterstützung.
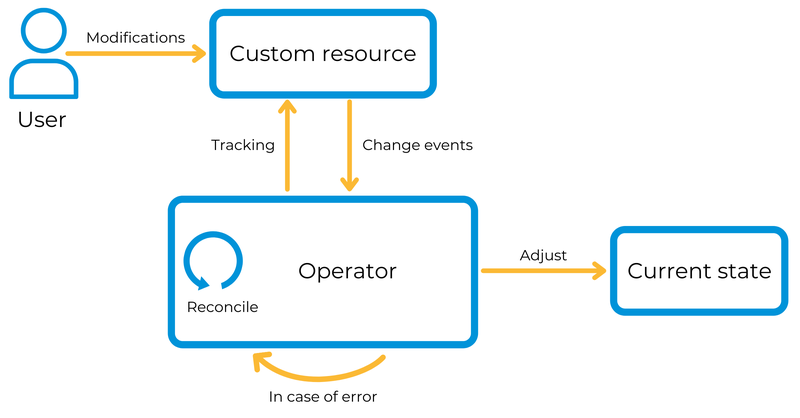
Diesen Operator-Pattern haben sich unterschiedliche kommerzielle und opensourced Projekte zunutze gemacht, indem sie Kafka Cluster Operatoren entwickelt haben. Es haben sich unterschiedliche Ansätze bewährt, wobei einer von Confluent, der treibenden Kraft hinter dem Open Source Projekt Apache Kafka konstruiert wurde, sowie ein Opensource Projekt namens Strimzi.
Immer mehr Unternehmen wagen den Schritt in die Cloud - und dies zurecht, denn die Vorteile liegen auf der Hand: Time-to-Market, Optimierung der Kosten, mehr Agilität, etc.
Gerade in Bezug auf Agilität kann die Cloud Punkten: Managed Kubernetes Cluster lassen sich mit wenigen Klicks oder CLI-Befehlen in der Cloud deployen und skalieren. Vorbei sind die Zeiten, wo man nach Erstellen eines Order-Tickets mehrere Tage auf die Bereitstellung eines Dienstes oder Systems wartet.
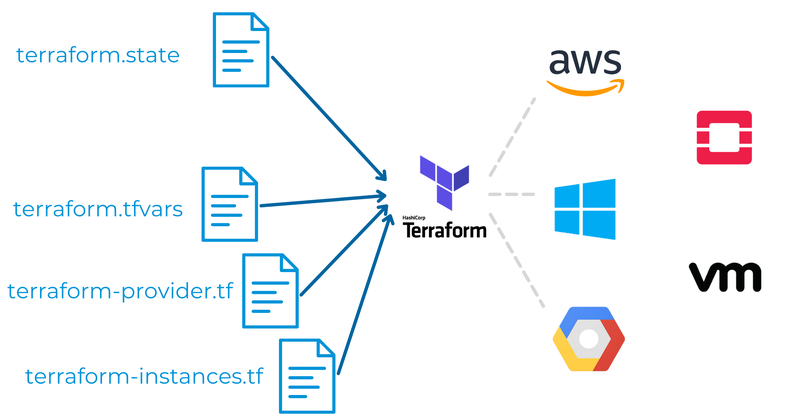
Während man für einen PoC ohne weiteres die Infrastruktur zusammenklicken kann, will man jedoch für ein produktives Setup diesen Prozess vorhersagbar und wiederholbar ausführen. Diese Aufgabe kann mit Hilfe von Infrastructure-as-code (IaC) Tools bewerkstelligt werden. Eines der bekanntesten Tools in diesem Bereich ist Terraform von Hashicorp. Mit Terraform lässt sich Cloud Infrastruktur deklarativ (also anhand eines gewünschten Zielzustandes) beschreiben und entsprechend provisionieren, und dies über sämtliche grosse Hyperscaler wie Google, Amazon, Microsoft oder auch Alibaba Cloud hinweg. Dies kann dann attraktiv werden, wenn man eine Hybrid-Cloud Strategie verfolgen will und somit mehrere Cloud-Provider gleichzeitig bedient.
Durch die Infrastrukturbeschreibung anhand von Zustandsdateien lässt sich das Ganze auch sehr gut in einen GitOps-Prozess integrieren. Das heisst, Änderungen an der Infrastruktur sind versioniert und können nur mit einem Approval durchgeführt werden.
Folgende Schritte sollten berücksichtigt werden, wenn man Kafka self-managed in der Public Cloud betreiben will:
Kombiniert man die Fähigkeiten eines Kafka Operators zusammen mit den Vorteilen der Public Cloud, hat man das Beste aus zwei Welten. Folgende Punkte sprechen für deren Einsatz:
Das Kafka Vorgehensmodell hilft Ihnen strukturiert vorzugehen.